# 互相关运算
| from symtable import Class |
| import torch |
| from torch import nn |
| from d2l import torch as d2l |
| |
| def corr2d(X,K): |
| h,w = K.shape |
| Y = torch.zeros((X.shape[0]-h+1,X.shape[1]-w+1)) |
| for i in range(Y.shape[0]): |
| for j in range(Y.shape[1]): |
| Y[i,j] = (X[i:i+h,j:j+w]*K).sum() |
| return Y |
| X = torch.tensor([[0,1,2],[3,4,5],[6,7,8]]) |
| K = torch.tensor([[0,1],[2,3]]) |
| corr2d(X,K) |
输出结果:
tensor([[19., 25.],
[37., 43.]])
# 卷积层
| |
| class Conv2D(nn.Module): |
| def __init__(self,kernel_size): |
| super().__init__() |
| |
| self.weight = nn.Parameter(torch.randn(kernel_size)) |
| self.bias = nn.Parameter(torch.zeros(1)) |
| |
| def forward(self,x): |
| |
| return corr2d(x,self.weight) + self.bias |
| X = torch.ones(6,8) |
| X[:,2:6] = 0 |
| X |
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
| K = torch.tensor([[1,-1]]) |
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
| |
| conv2d = nn.Conv2d(1,1,(1,2),bias=False) |
| |
| X = X.reshape((1,1,6,8)) |
| Y = Y.reshape((1,1,6,7)) |
| lr = 3e-2 |
| |
| for i in range(10): |
| Y_hat = conv2d(X) |
| |
| l = (Y_hat-Y)**2 |
| conv2d.zero_grad() |
| l.sum().backward() |
| conv2d.weight.data[:] -= lr*conv2d.weight.grad |
| if( i + 1) % 2 == 0: |
| print(f'epoch {i+1}, loss {float(l.sum()):f}') |
# 填充与步幅
| import torch |
| from torch import nn |
| def comp_conv2d(conv2d,X): |
| |
| X = X.reshape((1,1) + X.shape) |
| Y = conv2d(X) |
| return Y.reshape(Y.shape[2:]) |
| conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1) |
| X = torch.rand(size=(8,8)) |
| comp_conv2d(conv2d,X).shape |
| conv2d = nn.Conv2d(1,1,kernel_size=(3,5),padding=(0,1),stride=(3,4)) |
| comp_conv2d(conv2d,X).shape |
| |
| |
| |
# 多输入输出通道
| |
| from d2l import torch as d2l |
| |
| X = torch.tensor([[[0,1,2],[3,4,5],[6,7,8]],[[1,2,3],[4,5,6],[7,8,9]]]) |
| K = torch.tensor([[[0,1],[2,3]],[[1,2],[3,4]]],dtype=torch.float32) |
| def corr2d_multi_in(X,K): |
| return sum(d2l.corr2d(x,k) for x,k in zip(X,K)) |
| |
| def corr2d_multi_in_out(X,K): |
| return torch.stack([corr2d_multi_in(X,k) for k in K],0) |
| K = torch.stack((K,K+1,K+2),0) |
| K.shape |
torch.Size([3, 2, 2, 2])
输出结果
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
# 汇聚层
| import torch |
| from torch import nn |
| from d2l import torch as d2l |
| |
| def pool2d(X,pool_size,mode='avg'): |
| p_h,p_w = pool_size |
| Y = torch.zeros((X.shape[0]-p_h+1,X.shape[1]-p_w+1)) |
| for i in range(Y.shape[0]): |
| for j in range(Y.shape[1]): |
| if mode == 'avg': |
| Y[i,j] = X[i:i+p_h,j:j+p_w].mean() |
| elif mode == 'max': |
| Y[i,j] = X[i:i+p_h,j:j+p_w].max() |
| return Y |
构建输入张量,验证二维最大汇聚层输出
| X = torch.tensor([[0,1,2],[3,4,5],[6,7,8]],dtype=torch.float32) |
| pool2d(X,(2,2),'max') |
# 填充与步幅
| X = torch.arange(16,dtype=torch.float32).reshape((1,1,4,4)) |
| X |
| |
| pool2d = nn.MaxPool2d(kernel_size=3) |
| pool2d(X) |
| |
| pool2d = nn.MaxPool2d(kernel_size=3,padding=1,stride=2) |
| pool2d(X) |
# 多通道
| X = torch.cat((X,X+1),1) |
| X |
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])
| pool2d = nn.MaxPool2d(kernel_size=3,padding=1,stride=2) |
| pool2d(X) |
tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])
# 卷积神经网络(LeNet)
| |
| import torch |
| from torch import nn |
| from d2l import torch as d2l |
| |
| net = nn.Sequential( |
| nn.Conv2d(1,6,kernel_size=5,padding=2), |
| nn.Sigmoid(), |
| nn.AvgPool2d(kernel_size=2,stride=2), |
| nn.Conv2d(6,16,kernel_size=5,padding=0), |
| nn.Sigmoid(), |
| nn.AvgPool2d(kernel_size=2,stride=2), |
| nn.Flatten(), |
| nn.Linear(16*5*5,120), |
| nn.Sigmoid(), |
| nn.Linear(120,84), |
| nn.Sigmoid(), |
| nn.Linear(84,10) |
| ) |
| |
| X = torch.rand(size=(1,1,28,28),dtype=torch.float32) |
| for layer in net: |
| X = layer(X) |
| print(layer.__class__.__name__, 'output shape:\t', X.shape) |
输出结果(可口算一下 shape)
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
| batch_size = 256 |
| train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size) |
| def evaluate_accuracy_gpu(net,data_iter,device=None): |
| if isinstance(net,torch.nn.Module): |
| net.eval() |
| if not device: |
| device = next(iter(net.parameters())).device |
| |
| metric = d2l.Accumulator(2) |
| with torch.no_grad(): |
| for X,y in data_iter: |
| if isinstance(X,list): |
| X = [x.to(device) for x in X] |
| else: |
| X = X.to(device) |
| y = y.to(device) |
| metric.add(d2l.accuracy(net(X),y),y.numel()) |
| return metric[0]/metric[1] |
| |
| def train_ch6(net,train_iter,test_iter,num_epochs,lr,device): |
| def init_weights(m): |
| if type(m) == nn.Linear or type(m) == nn.Conv2d: |
| nn.init.xavier_uniform_(m.weight) |
| net.apply(init_weights) |
| print('training on',device) |
| net.to(device) |
| optimizer = torch.optim.SGD(net.parameters(),lr=lr) |
| loss = torch.nn.CrossEntropyLoss() |
| animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], |
| legend=['train loss', 'train acc', 'test acc']) |
| timer,num_batches = d2l.Timer(),len(train_iter) |
| |
| for epoch in range(num_epochs): |
| metric = d2l.Accumulator(3) |
| net.train() |
| for i,(X,y) in enumerate(train_iter): |
| timer.start() |
| optimizer.zero_grad() |
| X,y = X.to(device),y.to(device) |
| y_hat = net(X) |
| l = loss(y_hat,y) |
| l.backward() |
| optimizer.step() |
| with torch.no_grad(): |
| metric.add(l*X.shape[0],d2l.accuracy(y_hat,y),X.shape[0]) |
| timer.stop() |
| train_l = metric[0]/metric[2] |
| train_acc = metric[1]/metric[2] |
| if (i+1) % (num_batches//5) == 0 or i == num_batches-1: |
| animator.add(epoch + (i+1)/num_batches, |
| (train_l, train_acc, None)) |
| test_acc = evaluate_accuracy_gpu(net,test_iter) |
| animator.add(epoch+1, (None, None, test_acc)) |
| print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, test acc {test_acc:.3f}') |
| print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on {str(device)}') |
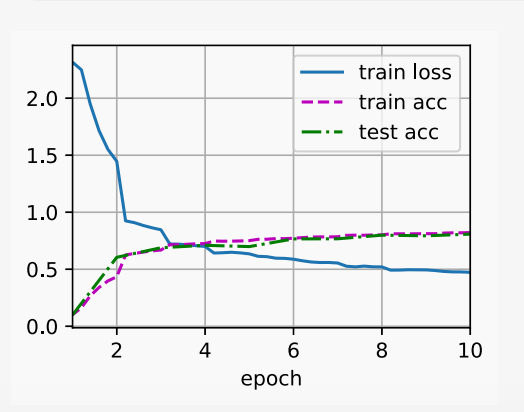
| lr,num_epochs = 0.9,10 |
| train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu()) |
loss 0.473, train acc 0.822, test acc 0.808
9342.8 examples/sec on cpu
![]()