# 逆向签到题
直接查看反汇编代码就能看到 flag
# re2
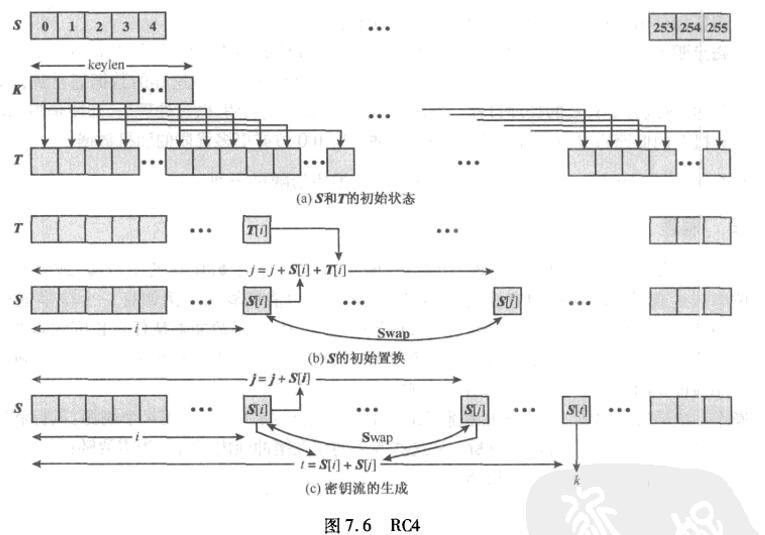
弄清楚加密过程 找到密钥 ,本题采用 RC4 加密,可以参考如下流程
讲解博客
将样本放进 IDA 中分析,在左侧找到_main 函数:
按下 tab,查看反汇编代码:

进入 main_0:
代码如下:
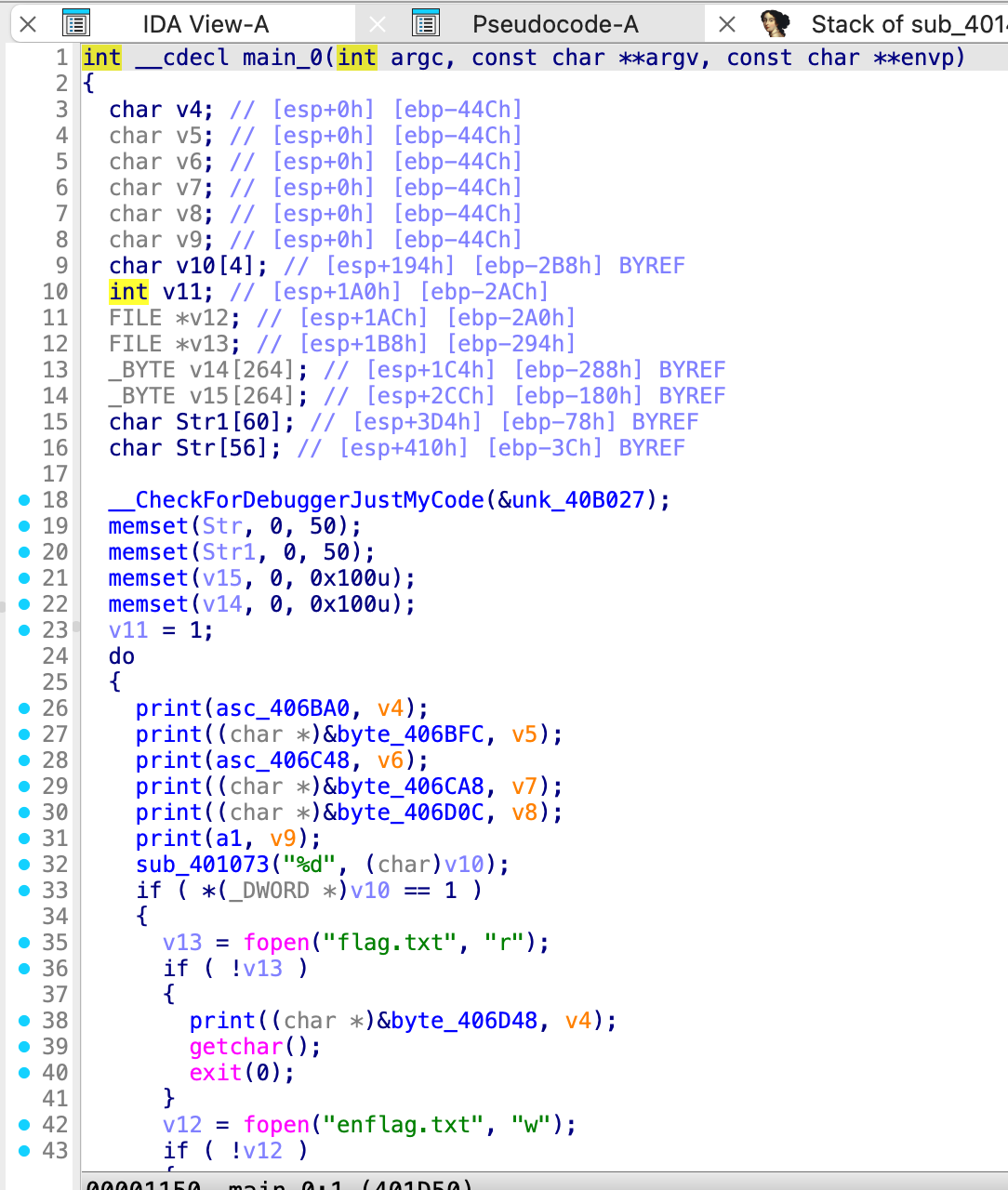
int __cdecl main_0(int argc, const char **argv, const char **envp) | |
{ | |
char v4; // [esp+0h] [ebp-44Ch] | |
char v5; // [esp+0h] [ebp-44Ch] | |
char v6; // [esp+0h] [ebp-44Ch] | |
char v7; // [esp+0h] [ebp-44Ch] | |
char v8; // [esp+0h] [ebp-44Ch] | |
char v9; // [esp+0h] [ebp-44Ch] | |
char v10[4]; // [esp+194h] [ebp-2B8h] BYREF | |
int v11; // [esp+1A0h] [ebp-2ACh] | |
FILE *v12; // [esp+1ACh] [ebp-2A0h] | |
FILE *v13; // [esp+1B8h] [ebp-294h] | |
_BYTE v14[264]; // [esp+1C4h] [ebp-288h] BYREF | |
_BYTE v15[264]; // [esp+2CCh] [ebp-180h] BYREF | |
char Str1[60]; // [esp+3D4h] [ebp-78h] BYREF | |
char Str[56]; // [esp+410h] [ebp-3Ch] BYREF | |
__CheckForDebuggerJustMyCode(&unk_40B027); | |
memset(Str, 0, 50); | |
memset(Str1, 0, 50); | |
memset(v15, 0, 0x100u); | |
memset(v14, 0, 0x100u); | |
v11 = 1; | |
do | |
{ | |
print(asc_406BA0, v4); | |
print((char *)&byte_406BFC, v5); | |
print(asc_406C48, v6); | |
print((char *)&byte_406CA8, v7); | |
print((char *)&byte_406D0C, v8); | |
print(a1, v9); | |
sub_401073("%d", (char)v10); | |
if ( *(_DWORD *)v10 == 1 ) | |
{ | |
v13 = fopen("flag.txt", "r"); | |
if ( !v13 ) | |
{ | |
print((char *)&byte_406D48, v4); | |
getchar(); | |
exit(0); | |
} | |
v12 = fopen("enflag.txt", "w"); | |
if ( !v12 ) | |
{ | |
print((char *)&byte_406D70, v4); | |
getchar(); | |
exit(0); | |
} | |
print(asc_406D84, v4); | |
sub_401073("%s", (char)Str); | |
sub_401069(Str, Str1); | |
sub_401028(Str, (int)v15, (int)v14, v13, v12); | |
} | |
else if ( *(_DWORD *)v10 == 2 ) | |
{ | |
v11 = 0; | |
} | |
else | |
{ | |
print(asc_406D98, v4); | |
} | |
} | |
while ( v11 ); | |
return 0; | |
} |
- v10 是我们输入的选项,为 1 的时候执行以下代码:
- 以只读的方式打开
flag.txt, 打开失败则退出 - 以写的方式打开
enflag.txt, 打开失败则退出 - 接下来输入一个字符串
Str - 最后执行两个函数
sub_401069,sub_401028
- 分析这两个函数
-
针对
sub_401069:// attributes: thunkint __cdecl sub_401069(char *Str, char *Str1)
{return sub_401A70(Str, Str1);
}进入 sub_401A70:
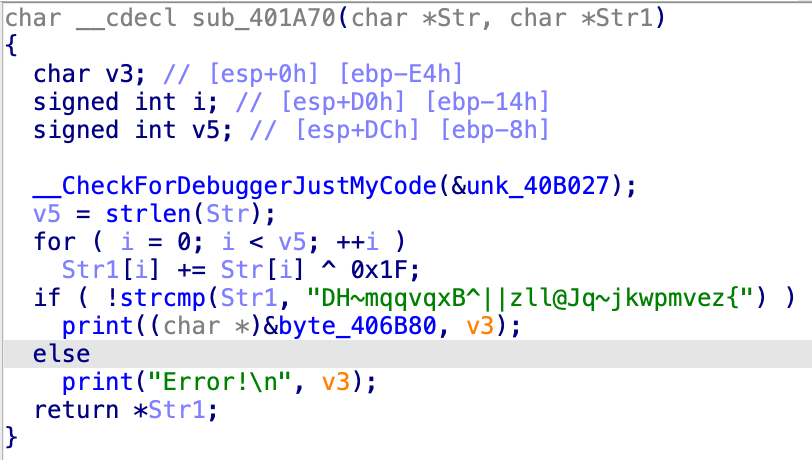
char __cdecl sub_401A70(char *Str, char *Str1)
{char v3; // [esp+0h] [ebp-E4h]
signed int i; // [esp+D0h] [ebp-14h]
signed int v5; // [esp+DCh] [ebp-8h]
__CheckForDebuggerJustMyCode(&unk_40B027);
v5 = strlen(Str);
for ( i = 0; i < v5; ++i )
Str1[i] += Str[i] ^ 0x1F;
if ( !strcmp(Str1, "DH~mqqvqxB^||zll@Jq~jkwpmvez{") )
print((char *)&byte_406B80, v3);
elseprint("Error!\n", v3);
return *Str1;
}![]()
这里接受两个参数 Str,Str1,其中 Str 是我们输入的参数,Str1 是主函数创建的长度为 50 字节的值为 0 的数组。程序流程如下:
- 将 Str1 中的每个字符与
0x1F异或 - 得到的新字符串与 "DH~mqqvqxB^||zll@Jq~jkwpmvez {" 进行比较
- 如果成功则返回字符串 Str1
这里可以先算一下 Str1:
cmp_str1 = "DH~mqqvqxB^||ll@Jq~jkwpmvez{"
plain_text = ""
for decrypted_char in cmp_str1:
plain_char = ord(decrypted_char) ^ 0x1f
plain_text += chr(plain_char)
print(plain_text)
![]()
可知
Str1 == [Warnning]Accss_Unauthorized,这也是我们需要输入的字符串。接下来点击 X 返回主函数:
- 将 Str1 中的每个字符与
-
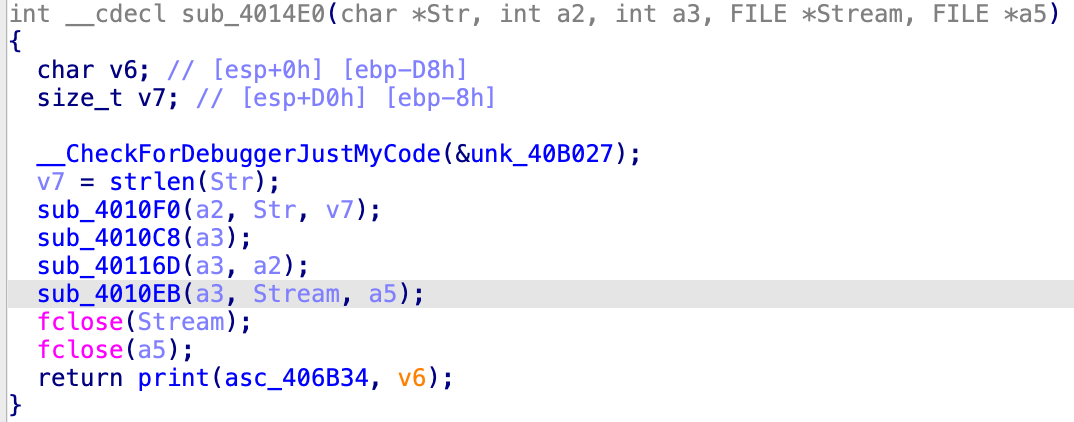
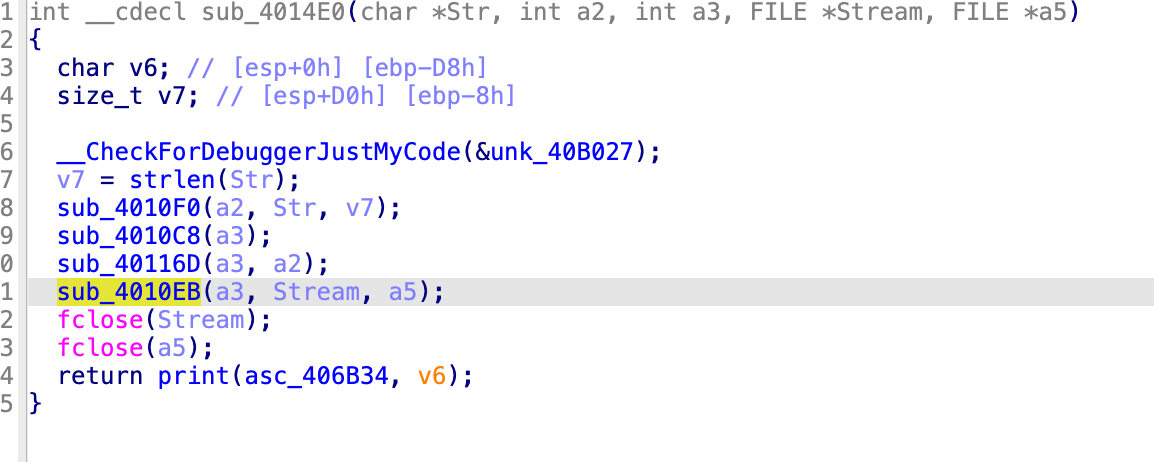
针对 sub_401028:
接收的参数有
sub_401028(Str, (int)v15, (int)v14, v13, v12), 跟进查看![]()
这里的
a2 = v15,a3 = v14,Stream = v13,a5 = v12,继续跟进![]()
继续跟进看到的四个函数
Sub_4010F0:
![]()
这里要注意的是 a1 是上一个函数里的 a2 也就是主函数的 v15,a2 是我们输入的字符串 ([Warnning] Accss_Unauthorized),a3 是我们输入的字符串的长度。
Sub_401800:
int __cdecl sub_401800(int a1, int a2, int a3)
{int result; // eax
int j; // [esp+D0h] [ebp-14h]
int i; // [esp+DCh] [ebp-8h]
result = __CheckForDebuggerJustMyCode(&unk_40B027);
if ( a3 <= 256 )
{for ( i = 0; i < 256; ++i )
{*(_BYTE *)(i + a1) = *(_BYTE *)(a2 + i % a3);
result = i + 1;
}}if ( a3 > 256 )
{for ( j = 0; j < 256; ++j )
{*(_BYTE *)(j + a1) = *(_BYTE *)(j + a2);
result = j + 1;
}}return result;
}接下来判断我们输入的字符串长度是否大于 256 ,如果不足 256,则复制 a2 ([Warnning] Accss_Unauthorized) 直到长度大于 256。如果超过 256,则截断。所以这个函数主要是改变了主函数里的 v15。
sub_4010c8:
![]()
![]()
这里的 a1 是主函数里的 v14。只是初始化了一个数组 并把这个数组每个值赋值为索引。
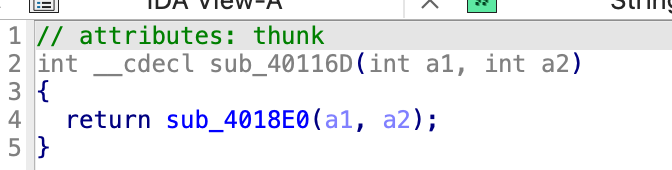
sub_40116D:
接收的参数分别为 a3,a2, 即主函数里的 v14,v15。由于 v14 之前提到过则记录一下 他是一个索引为值的数组,v15 是第一个函数 256 位处理的那个
![]()
继续跟进得到下面的函数
int __cdecl sub_4018E0(int a1, int a2)
{int result; // eax
int i; // [esp+D0h] [ebp-2Ch]
char v4; // [esp+EBh] [ebp-11h]
int v5; // [esp+F4h] [ebp-8h]
result = __CheckForDebuggerJustMyCode(&unk_40B027);
v5 = 0;
for ( i = 0; i < 256; ++i )
{v5 = (*(unsigned __int8 *)(i + a2) + v5 + *(unsigned __int8 *)(i + a1)) % 256;
v4 = *(_BYTE *)(i + a1);
*(_BYTE *)(i + a1) = *(_BYTE *)(v5 + a1);
*(_BYTE *)(v5 + a1) = v4;
result = i + 1;
}return result;
}这里需要把 a1 认为是 v14,a2 认为是 v15
这里是把两个数组的每一位分别做计算之后通过 v5 这个变量累加起来。v4 就是 a1 这个数组的第 i 位,之后将 a1 这个数组的 v5 这个位置的值放入 v4,将 v4 放入 v5 的这个位置。也就是将 a1 的第 i 个位置与第 v5 个位置的值进行置换。
这个函数改变的就是 a1 就是主函数的 v14,类似于做了个初始置换.
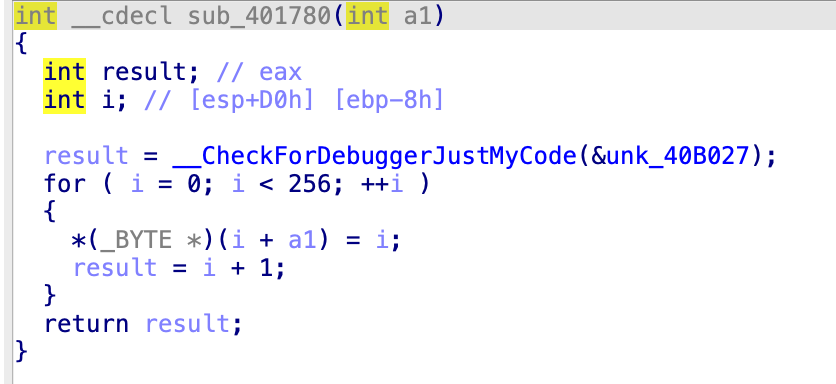
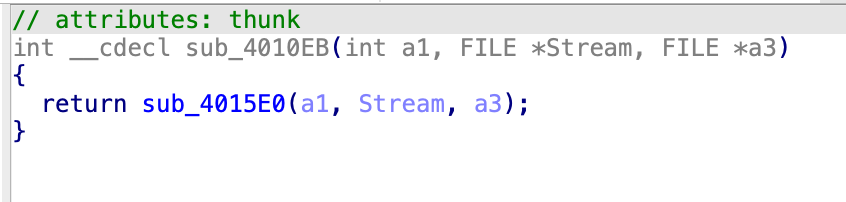
看最后一个函数:
4010EB:
接收的参数为 sub_4010EB (a3, Stream, a5); 也就是主函数的 v14,v13,v12(这两是和 flag 有关的文件)
![]()
跟进:
![]()
![]()
这里的 a1 就是 v14,stream 就是 v13,a3 就是 v12
代码可知:
- 循环读取 v13 (flag.txt) 中的字符,v7 很显然代表的是读取字符的位置(在文件中的第几位),v6 就是 v14 文件中对应位置的字符并与 v6 累加。
- 接下来三行代码是将 v14 文件中的 v6 位置的字符与 v7 位置的字符进行替换。
- 最后将 v14 文件中的 v6 位置的字符与 v7 位置的字符转成数字后累加得到的值作为索引 t,拿到 v14 文件中的第 t 个字符并与源码中的
i(这个 i 是原本的 flag 哈) 进行异或之后写入 v2 (enflag.txt), 即加密后的文件


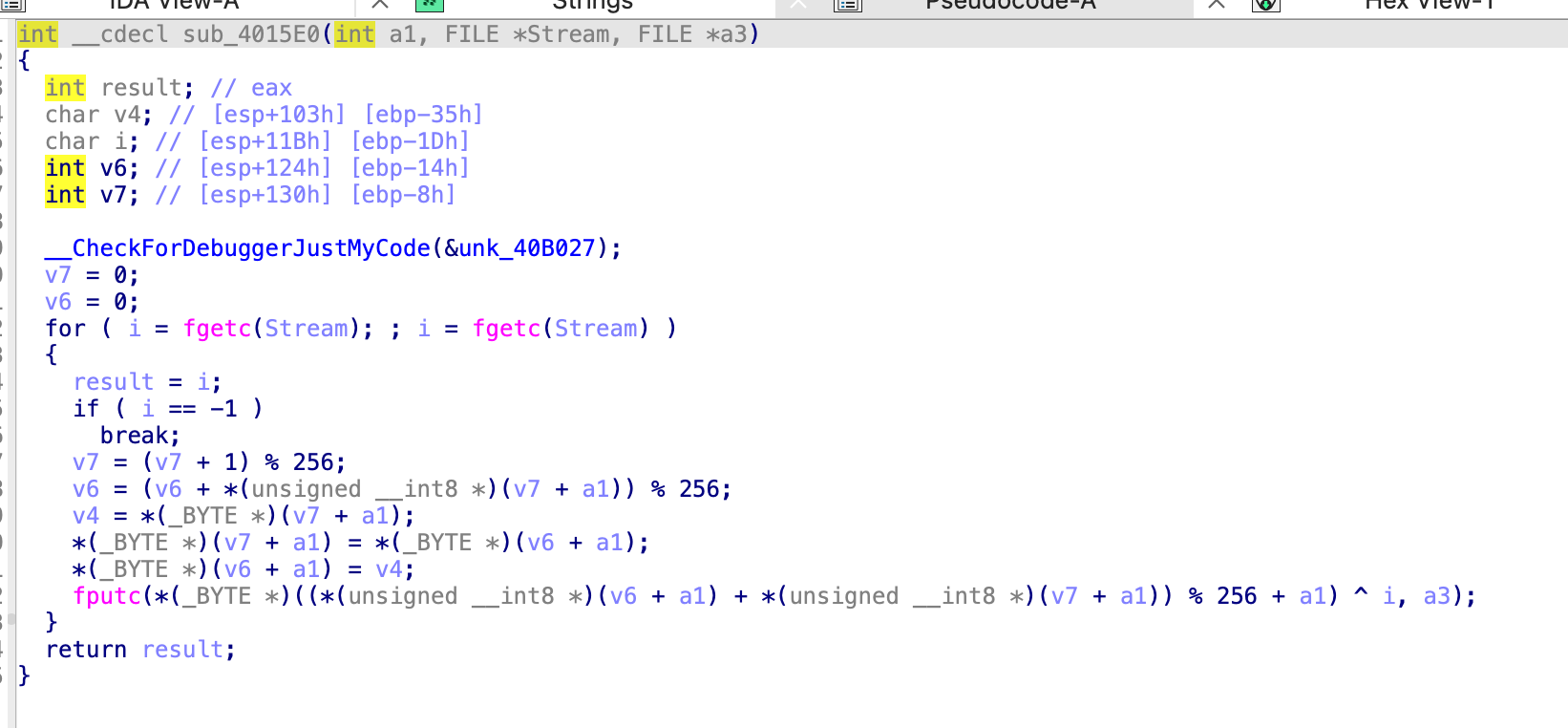
- 综上,整个过程就是 RC4 的实现方式
- 不难看出我们输入的 Str 实际就是密钥,密钥为
[Warnning]Accss_Unauthorized - v14 对应的就是 RC4 中的 S 盒,V15 对应的就是 T,我们通过输入的密钥不断填充 V15。
- 之后就是 V14 与 V15 直接的运算包括 S 的初始置换以及最后密钥流的生成。
- 不难看出我们输入的 Str 实际就是密钥,密钥为
- 之后编写解密代码 ,我们可以拿到加密后 flag 的值 ,通过分析也得到了密钥
[Warnning]Accss_Unauthorized之后我们就需要按照 RC4 的方式同样生成密钥流,最后对密文进行解密。
# | |
# 根据 IDA 逆向分析结果编写的 RC4 解密脚本 | |
# | |
# ========================== 用户配置区 ========================== | |
# ❗️ 在这里填入加密时使用的密钥 | |
YOUR_SECRET_KEY = "[Warnning]Access_Unauthorized" | |
# ❗️ 填入加密后的文件名 (即 enflag.txt 的路径) | |
ENCRYPTED_FILE_PATH = "enflag.txt" | |
# ❗️ 填入保存解密后文件的名字 | |
DECRYPTED_FILE_PATH = "flag_decrypted.txt" | |
# ============================================================= | |
class RC4: | |
def __init__(self, key: str): | |
""" | |
使用密钥初始化RC4状态,完成密钥调度算法(KSA)。 | |
这个构造函数完整复刻了 sub_401780, sub_401800, 和 sub_4018E0 的功能。 | |
""" | |
key_bytes = key.encode('ascii') # 将字符串密钥转为字节 | |
key_length = len(key_bytes) | |
# 对应 sub_401780: 初始化 S-box, S [i] = i | |
self.S = list(range(256)) | |
# 对应 sub_401800: 根据密钥初始化 T-vector | |
T = [key_bytes[i % key_length] for i in range(256)] | |
# 对应 sub_4018E0: 使用 T-vector 对 S-box 进行初始置换 | |
j = 0 | |
for i in range(256): | |
j = (j + self.S[i] + T[i]) % 256 | |
# 交换 S [i] 和 S [j] | |
self.S[i], self.S[j] = self.S[j], self.S[i] | |
print("✅ RC4 状态初始化完成 (KSA complete).") | |
def crypt(self, data: bytes) -> bytes: | |
""" | |
对数据进行加密或解密。 | |
这个方法完整复刻了 sub_4015E0 (PRGA) 的功能。 | |
""" | |
i = 0 | |
j = 0 | |
output = bytearray() | |
for byte in data: | |
i = (i + 1) % 256 | |
j = (j + self.S[i]) % 256 | |
# 交换 S [i] 和 S [j] | |
self.S[i], self.S[j] = self.S[j], self.S[i] | |
# 计算 t 并生成密钥流字节 k | |
t = (self.S[i] + self.S[j]) % 256 | |
keystream_byte = self.S[t] | |
# 将数据字节与密钥流字节进行 XOR | |
output.append(byte ^ keystream_byte) | |
return bytes(output) | |
# --- 主执行逻辑 --- | |
if __name__ == "__main__": | |
print("--- RC4解密程序启动 ---") | |
# 检查密钥是否已填写 | |
try: | |
# 1. 读取加密后的文件内容 | |
print(f"📄 正在读取加密文件: {ENCRYPTED_FILE_PATH}") | |
with open(ENCRYPTED_FILE_PATH, 'rb') as f: | |
encrypted_data = f.read() | |
print(f" 读取了 {len(encrypted_data)} 字节数据。") | |
# 2. 使用密钥初始化 RC4 加密器 | |
print(f"🔑 使用密钥 '{YOUR_SECRET_KEY}' 初始化RC4...") | |
cipher = RC4(YOUR_SECRET_KEY) | |
# 3. 执行解密 (与加密过程完全相同) | |
print("⚙️ 正在执行解密操作...") | |
decrypted_data = cipher.crypt(encrypted_data) | |
print(" 解密完成。") | |
# 4. 将解密后的数据写入新文件 | |
print(f"💾 正在将解密结果写入文件: {DECRYPTED_FILE_PATH}") | |
with open(DECRYPTED_FILE_PATH, 'wb') as f: | |
f.write(decrypted_data) | |
print("\n" + "=" * 50) | |
print(f"🎉 解密成功!结果已保存至 {DECRYPTED_FILE_PATH}") | |
print("=" * 50) | |
except FileNotFoundError: | |
print(f"❌ 错误: 找不到文件 '{ENCRYPTED_FILE_PATH}'。请检查文件名和路径是否正确。") | |
except Exception as e: | |
print(f"❌ 发生未知错误: {e}") |
# Re3
本题比较简单,没有跨函数分析:
int __fastcall main(int argc, const char **argv, const char **envp) | |
{ | |
size_t v3; // rax | |
int v5; // [rsp+Ch] [rbp-134h] BYREF | |
unsigned int i; // [rsp+10h] [rbp-130h] | |
int v7; // [rsp+14h] [rbp-12Ch] | |
int v8; // [rsp+18h] [rbp-128h] | |
int v9; // [rsp+1Ch] [rbp-124h] | |
int v10; // [rsp+20h] [rbp-120h] | |
int v11; // [rsp+24h] [rbp-11Ch] | |
int v12; // [rsp+28h] [rbp-118h] | |
int v13; // [rsp+2Ch] [rbp-114h] | |
int v14; // [rsp+30h] [rbp-110h] | |
int v15; // [rsp+34h] [rbp-10Ch] | |
unsigned __int64 v16; // [rsp+38h] [rbp-108h] | |
_DWORD v17[8]; // [rsp+40h] [rbp-100h] | |
char s[5]; // [rsp+60h] [rbp-E0h] BYREF | |
char v19[107]; // [rsp+65h] [rbp-DBh] BYREF | |
char dest[104]; // [rsp+D0h] [rbp-70h] BYREF | |
unsigned __int64 v21; // [rsp+138h] [rbp-8h] | |
v21 = __readfsqword(0x28u); | |
v7 = 80; | |
v8 = 64227; | |
v9 = 226312059; | |
v10 = -1540056586; | |
v11 = 5; | |
v12 = 16; | |
v13 = 3833; | |
v5 = 0; | |
puts("plz input the key:"); | |
__isoc99_scanf("%s", s); | |
v3 = strlen(s); // 判断输入字符的长度 | |
strncpy(dest, v19, v3 - 6); | |
dest[strlen(s) - 6] = 0; | |
__isoc99_sscanf(dest, "%x", &v5); | |
v17[0] = v7; | |
v17[1] = v8; | |
v17[2] = v9; | |
v17[3] = v10; | |
v17[4] = (v11 << 12) + v12; | |
v17[5] = v13; | |
v17[6] = v5; | |
v16 = 0; | |
for ( i = 0; i <= 6; ++i ) | |
{ | |
for ( v16 += (unsigned int)v17[i]; v16 > 0xFFFF; v16 = v15 + (unsigned int)(unsigned __int16)v16 ) | |
{ | |
v14 = (unsigned __int16)v16; | |
v15 = v16 >> 16; | |
} | |
} | |
if ( v16 == 0xFFFF ) | |
puts("OK"); | |
else | |
puts("Error"); | |
return 0; | |
} |
-
整体流程:
- 初始化变量后,需要输入一个字符串
- 从第六位开始截取这个字符串并 copy 给 dest,注意这里输入的时候是给的 s 但是由于 s 的长度只有 5 而且紧接着 s 下面就是 v19,所以我们输入的字符串超过 5 位后的字符都会被存在 v19
- 将 dest 中的值以十六进制的形式读给 v5
- 初始化 v17 数组
- 之后进行六次循环
- 将 v16 加上 v17 对应位置的值
- 如果超过了 ffff 那么将 v16 保存到 v14,之后右移 16 位并与自己累加
- 循环完成之后,如果得到 v16 恰好是 ffff 则输出 OK。
-
写脚本求输入的字符串,使得 v16 恰好为 ffff
分析算法过程:
![]()
根据分析过程编写如下代码:

#!/usr/bin/env python3 | |
# -*- coding: utf-8 -*- | |
def calculate_hex_key(): | |
""" | |
根据已知的校验和算法和 "%x" 格式,直接计算出最终的key。 | |
""" | |
# 1. 初始化常量 | |
s_fixed_values = [ | |
0x50, # s[0] = x | |
0xfae3, # s[1] = c | |
0xd7d3f7b, # s[2] = v | |
0xa43499f6, # s[3] = n | |
0x10 + 5 * 0x1000, # s[4] = m + b * 0x1000 | |
0xef9 # s[5] = h | |
] | |
# 2. 计算已知数值的总和 | |
fixed_sum = sum(s_fixed_values) | |
# 3. 模拟 C 代码中的校验和折叠算法 | |
def checksum_fold(value): | |
while value > 0xffff: | |
value = (value & 0xffff) + (value >> 16) | |
return value | |
# 4. 计算部分校验和 | |
partial_checksum = checksum_fold(fixed_sum) | |
# 5. 根据目标 0xffff 计算出 j 的值 | |
target = 0xffff | |
j = target - partial_checksum | |
# 6. 构造最终的 key | |
# 格式为 "% x",所以使用 j 的十六进制字符串表示 | |
# 末尾附加任意 6 个字符以满足程序的长度要求 | |
final_key = f"{j:x}" + "A" * 6 | |
print("=" * 40) | |
print("已确认 sscanf 格式为 '%x'.") | |
print(f"计算出的 j 的值: 0x{j:x}") | |
print(f"因此, 正确的 Key 是: {final_key}") | |
print("=" * 40) | |
if __name__ == "__main__": | |
calculate_hex_key() |
得到输入的值应该是 0x1a9f:
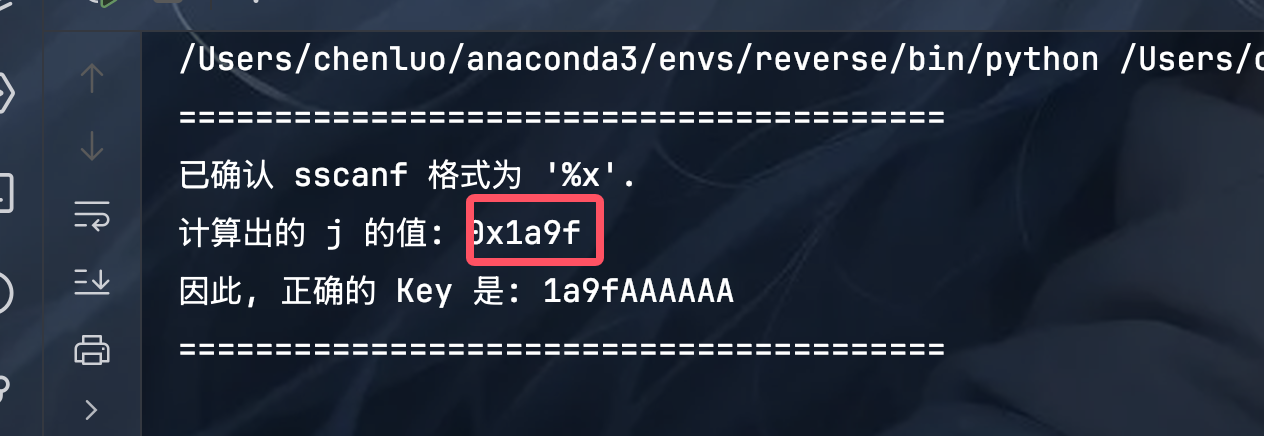
# re4
查看 main 函数
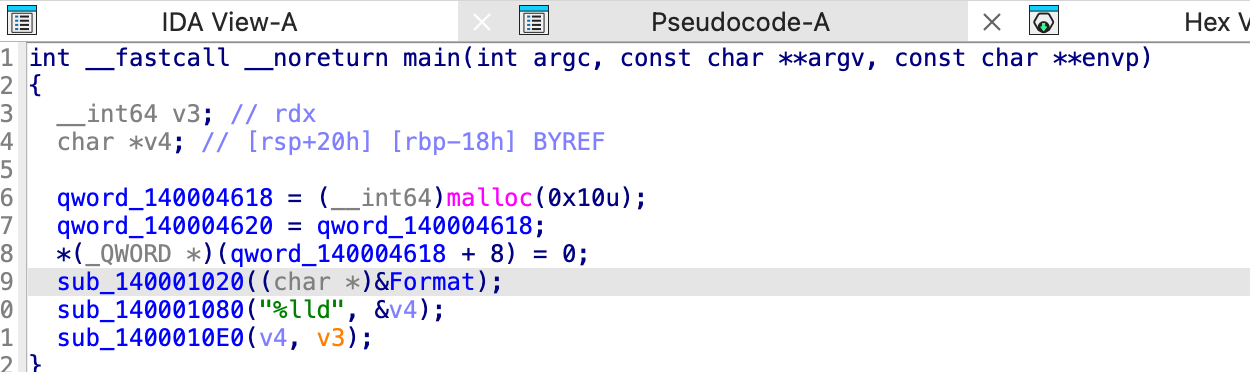
v4 是我们需要输入的值,直接跳到 sub_1400010E0 函数:
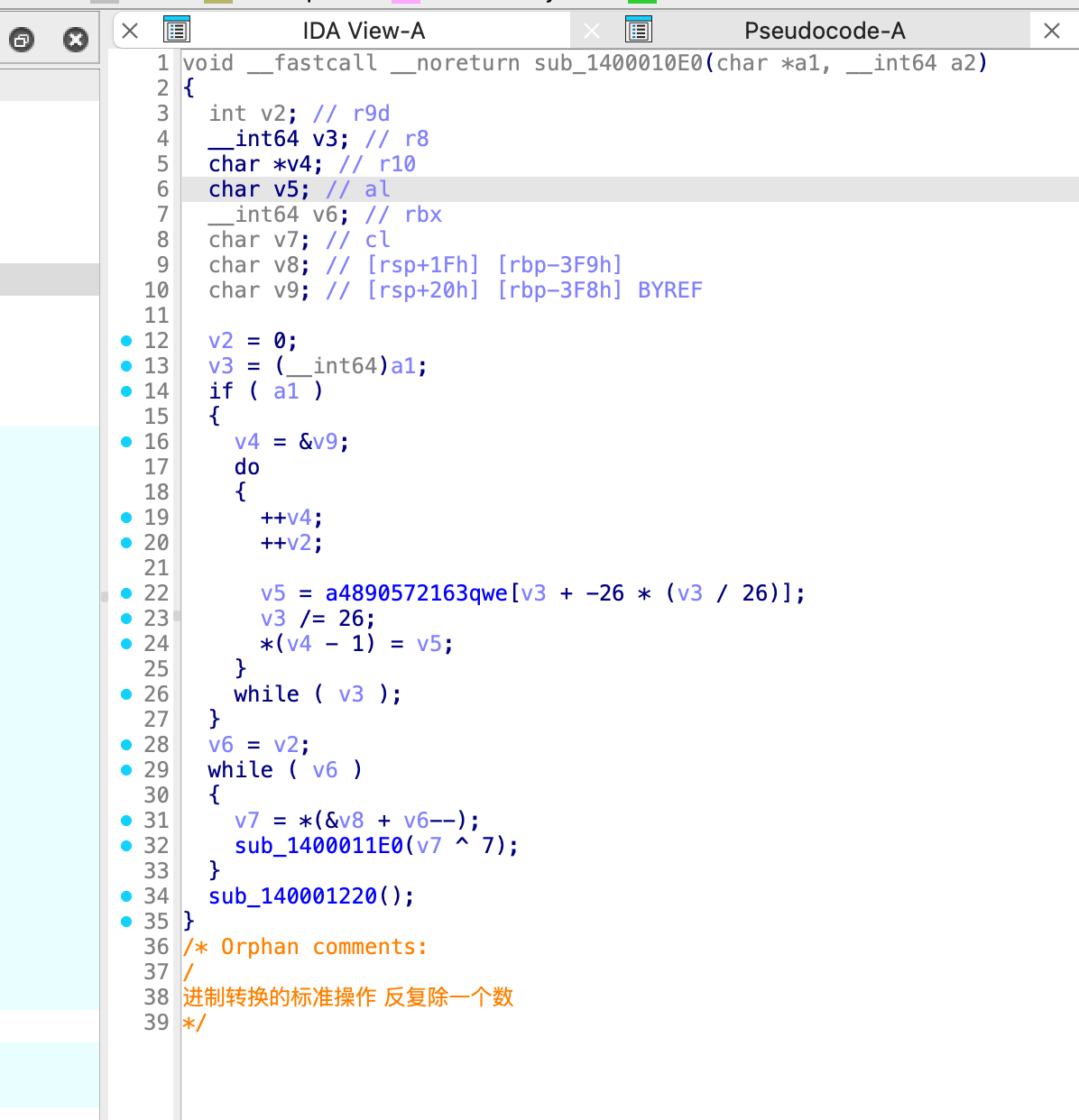
这里的 a1 就是 v4(我们输入的字符串)
先要看懂 v3 + -26 * (v3 / 26) 实际上就是 v3%26
由于循环中 v5 = a4890572163qwe[v3 + -26 * (v3 / 26)]; 在不停除以 26,则实际上是将 v3 转换成一个 26 进制的数,这个数的每一位作为 a4890572163qwe 字符串的索引取值放进 v4 这个字符串中,所以我们得先求 v4, 由于目前不知道我们需要输入的字符串我们接着往下看。
v2 代表的是转换为 26 进制之后的位数
下面的循环:
由于 v8 和 v9 都是 char 类型,所以 v8+1 就是 v9,所以 v7 = *(&v8 + v6--);
v7 为 v3 的逆序的每一个字符
查看字符串 a4890572163qwe:
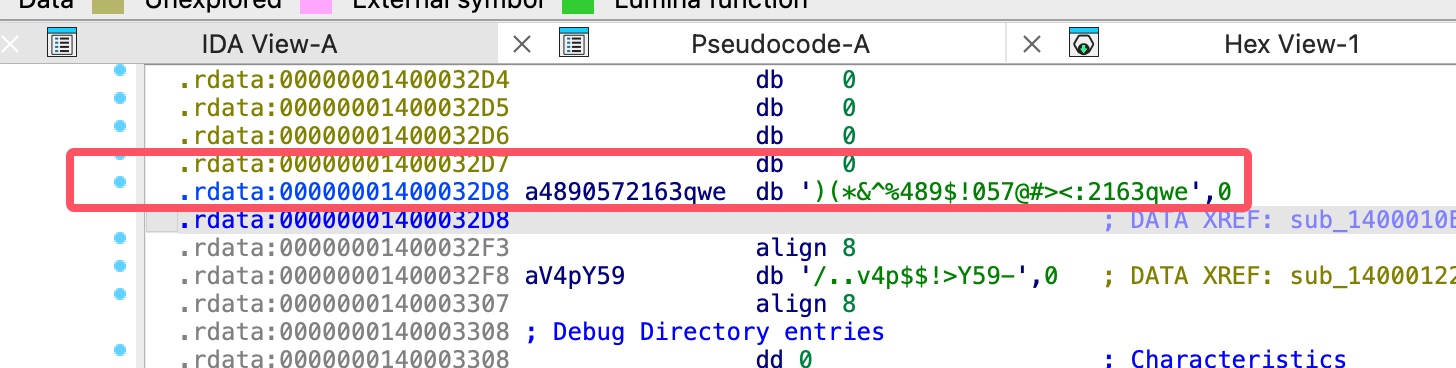
接下来看 sub_1400011E0:
sub_1400011E0 (v7 ^ 7); 该函数先将每个字符与 7 进行异或作为函数的参数
_QWORD *__fastcall sub_1400011E0(char a1) | |
{ | |
_QWORD *result; // rax | |
__int64 v3; // rdx | |
result = malloc(0x10u); | |
v3 = qword_140004618; | |
qword_140004618 = (__int64)result; | |
*(_QWORD *)(v3 + 8) = result; | |
*(_BYTE *)v3 = a1; | |
result[1] = 0; | |
return result; | |
} |
这里就是把与 7 异或完的字符放进数组里组成完整的字符串。
这里要留意下数组的地址是 qword_140004618,接着返回主函数,继续分析下一个函数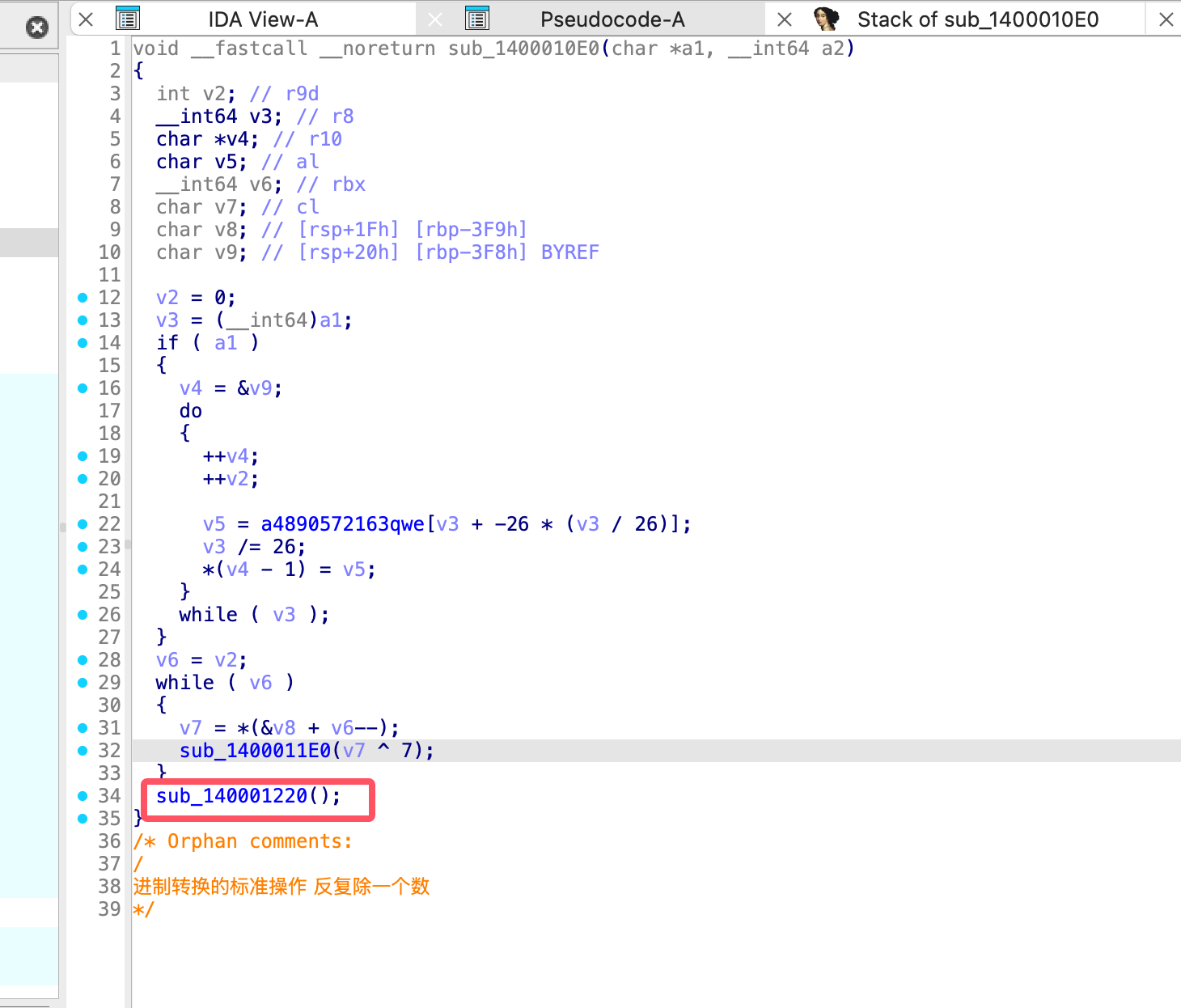
void __noreturn sub_140001220() | |
{ | |
__int64 v0; // r9 | |
int v1; // ecx | |
__int64 v2; // rdx | |
char v3; // al | |
int v4; // r8d | |
__int64 v5; // r9 | |
char v6; // cl | |
int v7; // eax | |
v0 = qword_140004620; | |
v1 = 0; | |
v2 = 0; | |
while ( 1 ) | |
{ | |
v3 = *(_BYTE *)v0; | |
v4 = v1 + 1; | |
v5 = *(_QWORD *)(v0 + 8); | |
if ( v3 != aV4pY59[v2] ) | |
v4 = v1; | |
qword_140004620 = v5; | |
if ( !v5 ) | |
break; | |
v6 = *(_BYTE *)v5; | |
v7 = v4 + 1; | |
v0 = *(_QWORD *)(v5 + 8); | |
if ( v6 != aV4pY59[v2 + 1] ) | |
v7 = v4; | |
qword_140004620 = v0; | |
if ( v0 ) | |
{ | |
v2 += 2; | |
v1 = v7; | |
if ( v2 < 14 ) | |
continue; | |
} | |
goto LABEL_11; | |
} | |
v7 = v4; | |
LABEL_11: | |
if ( v7 == 14 ) | |
sub_1400012E0(); | |
sub_1400012B0(); | |
} |
这里就是从我们刚才的字符串数组开始与字符串 aV4pY59 进行比较,我们先获得该字符串:

最终就是逐位比较这 14 位的字符串如果比较成功那么 v7 刚好等于 14 则执行 12E0 函数会给出 flag。
接下来编写脚本,获取我们要输入的字符串:
-
首先根据密文 /…v4p$$!>Y59-,每一位与 7 异或回退到进入函数前:
target_ciphertext = "/..v4p$$!>Y59-"
decrypted_list = [chr(ord(c) ^ 7) for c in target_ciphertext]
decrypted_string = "".join(decrypted_list)
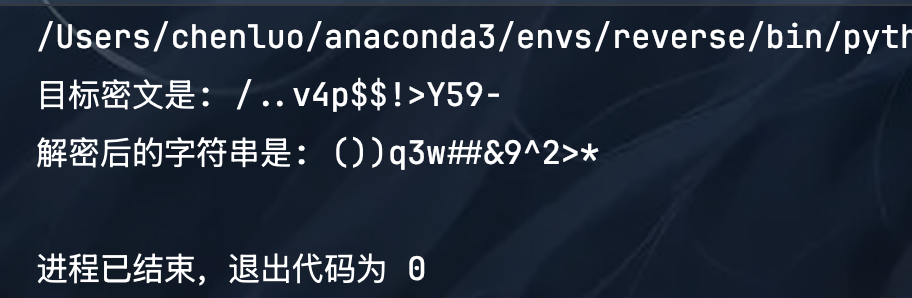
print(f"目标密文是: {target_ciphertext}")
print(f"解密后的字符串是: {decrypted_string}")
![]()
-
根据得到的解密后的字符串 ()) q3w##&9^2>* 继续逆推:
- ())q3w##&9^2>*
- 找到 ()) q3w##&9^2> 每个字符在原本字符 (")(&^%489$!057@#><:2163qwe") 的索引
- 最后将获取到的索引值转换成十进制
alphabet = ")(*&^%489$!057@#><:2163qwe"
base26_string = "())q3w##&9^2>*"
final_number = 0
for char in base26_string:
# 找到字符在字母表中的位置(索引)digit_value = alphabet.find(char)
if digit_value == -1:
print(f"错误: 字符 '{char}' 不在字母表中!")
break# 核心转换算法final_number = final_number * 26 + digit_value
print(f"最终的密码 (输入数字) 是: {final_number}")
![输入的密钥]()

# Re5
先直接说结果:
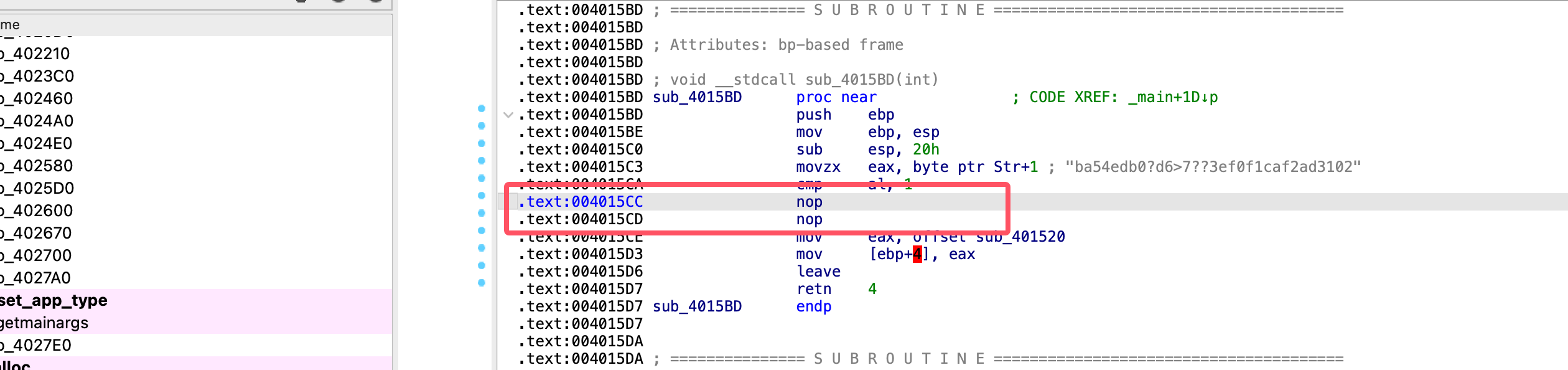
把这里原本的 jnz 语句改成两个 nop 即可;
还是分析 main 函数:
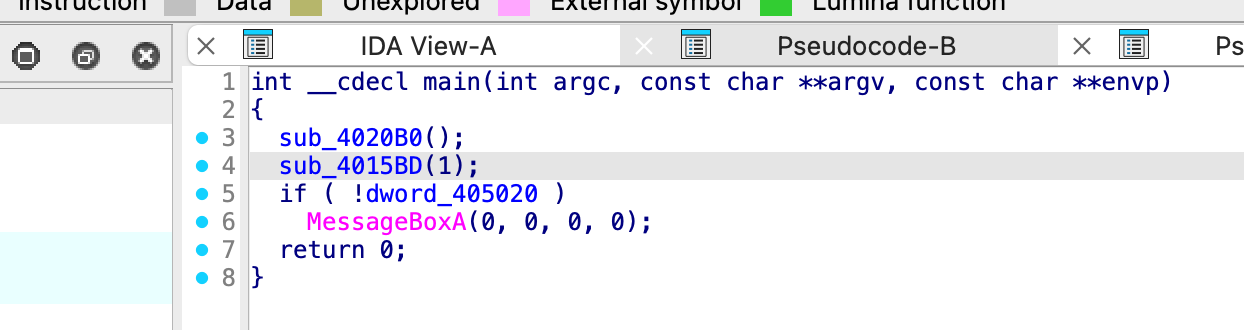
sub_4020B0 () 是做一些静态初始化
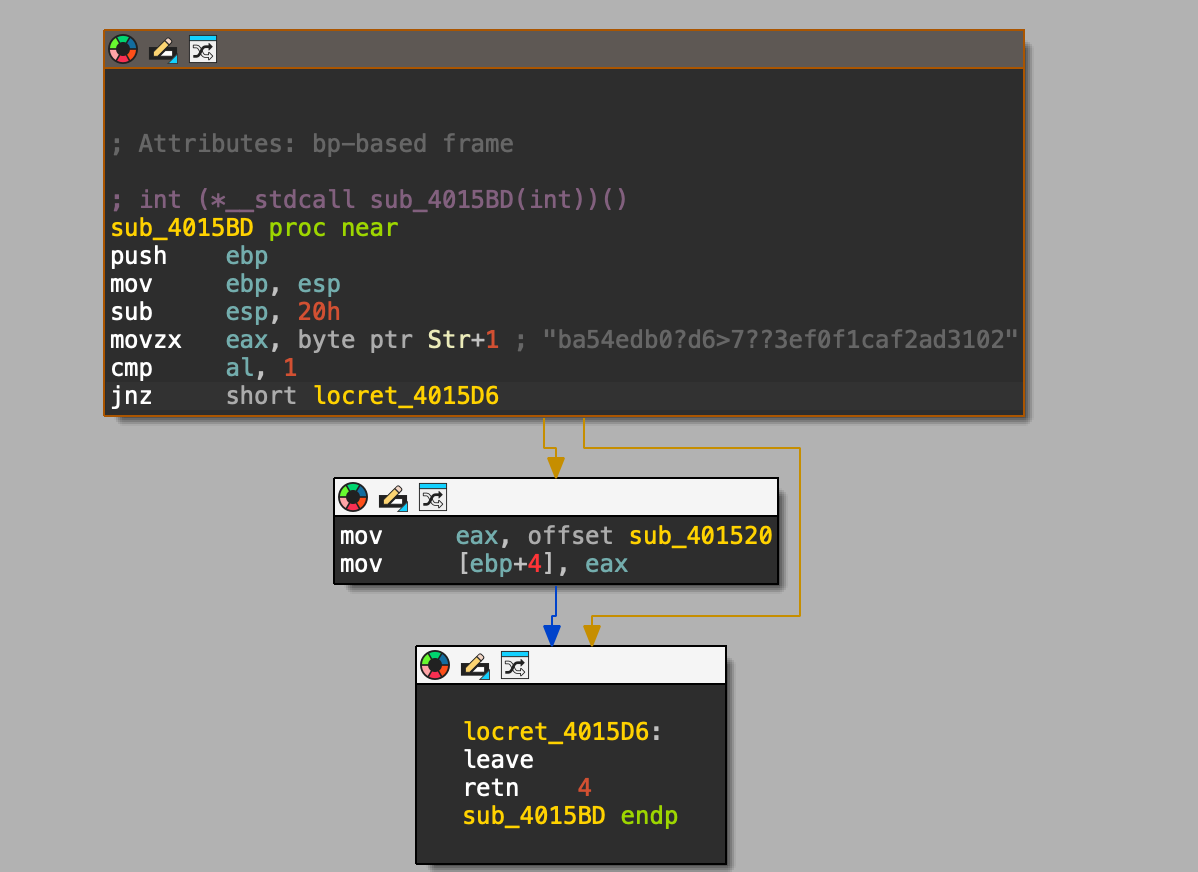
sub_4015BD () 函数
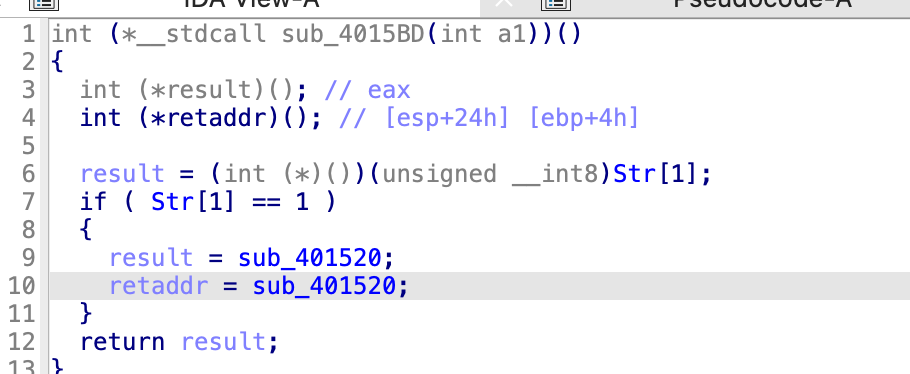
这里会比较 Str 这个字符串是不是 1,如果是的话执行下面的函数 不是的话就退出
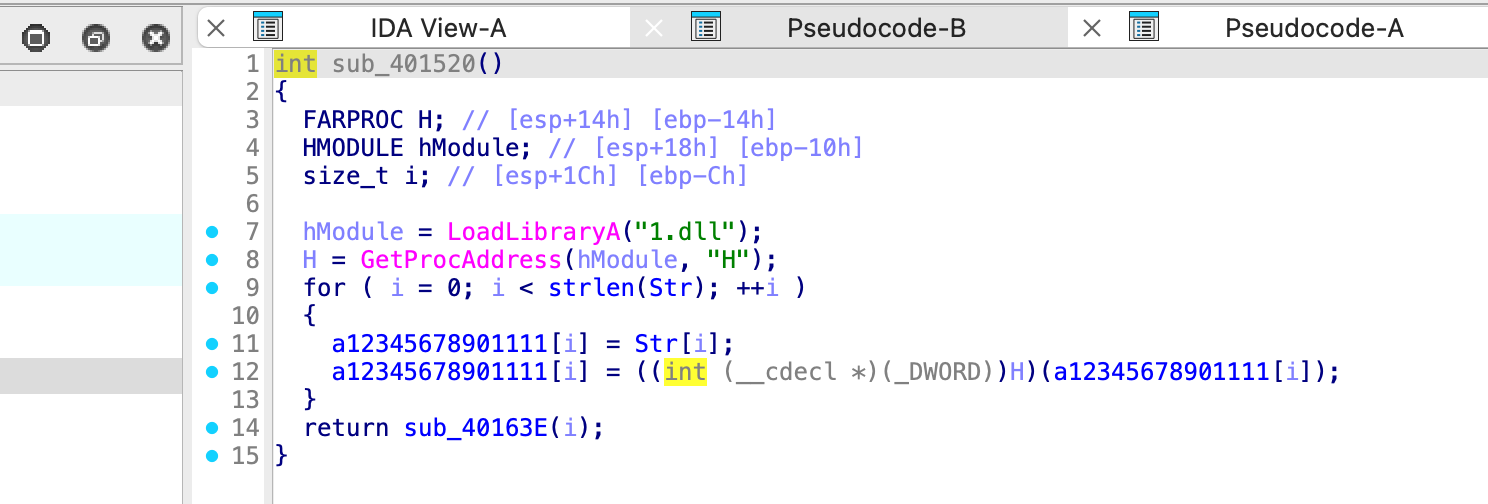
我们先看一下 Str 的值,如下图,很显然第二位不是 1。
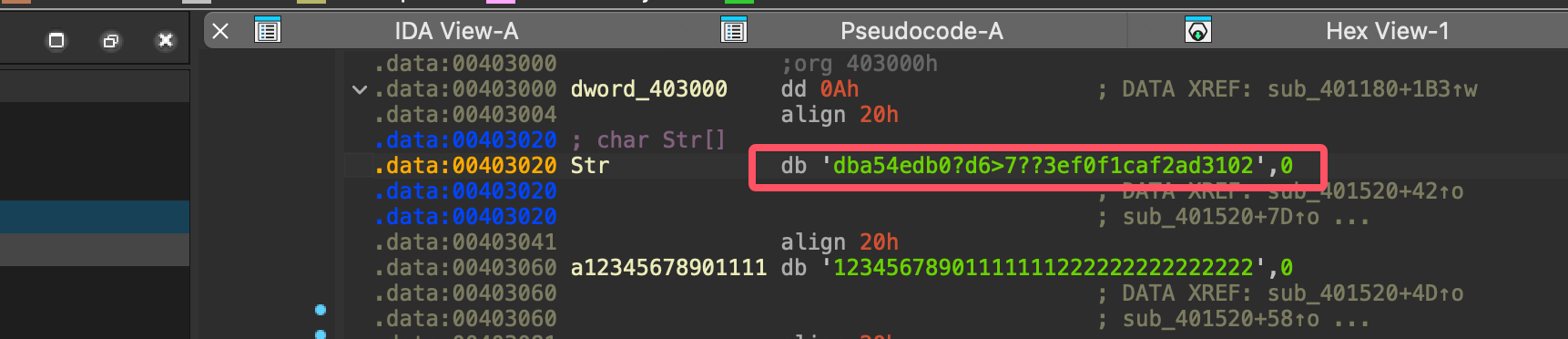
Sub_401520 函数这里会调用一个 1.dll 中的 H 函数,逐位进行加 / 解密
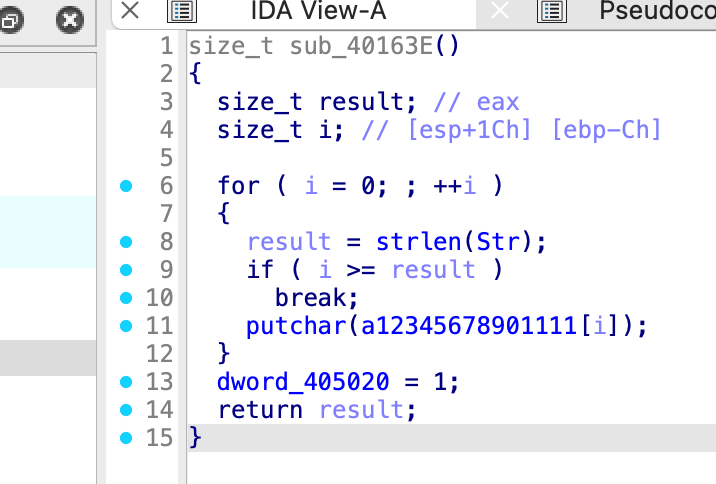
最后进行输出
所以 有两种方法:
一个是修改字符串的值,另一个是修改汇编语句
到 CMP 指令之后的那条条件跳转指令,例如 JNZ short loc_XXXXXX (如果不相等就跳转)。
用 NOP 替换指令: NOP (No Operation, 空操作) 是一个 CPU 指令,它什么也不做,只会让程序执行下一条指令。我们可以用它来 “抹掉” 不想要的指令。
由于一个 jnz 指令的长度是两个字节,而 NOP 指令的长度只有一个字节,必须使用两个 1 字节的指令去填满原来两字节的空间,最后得到如下
变成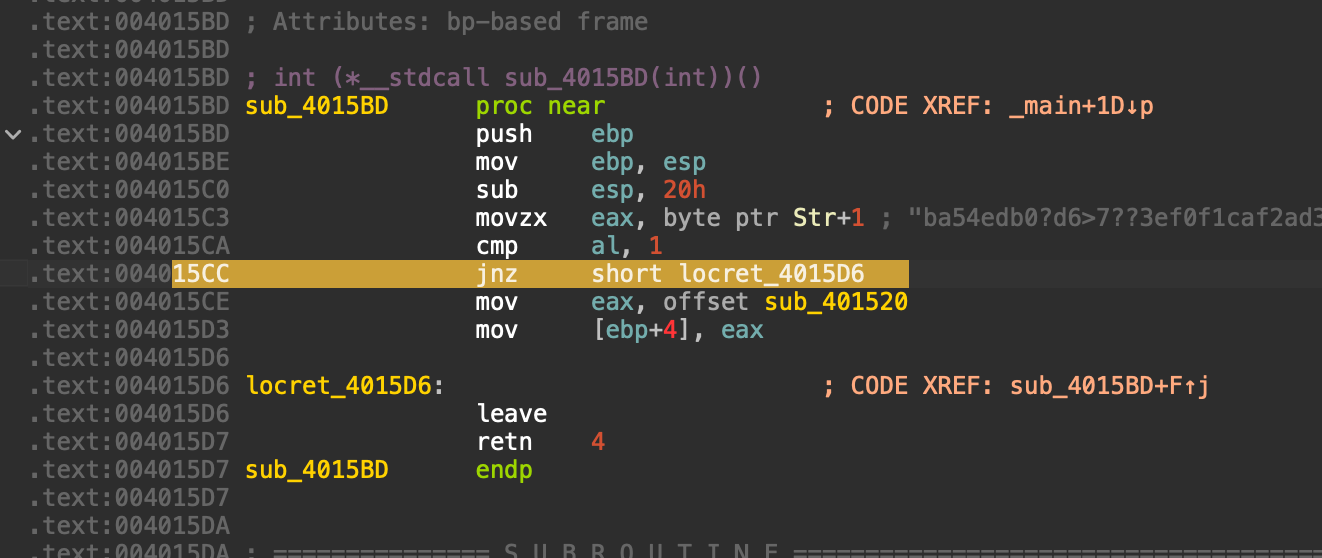
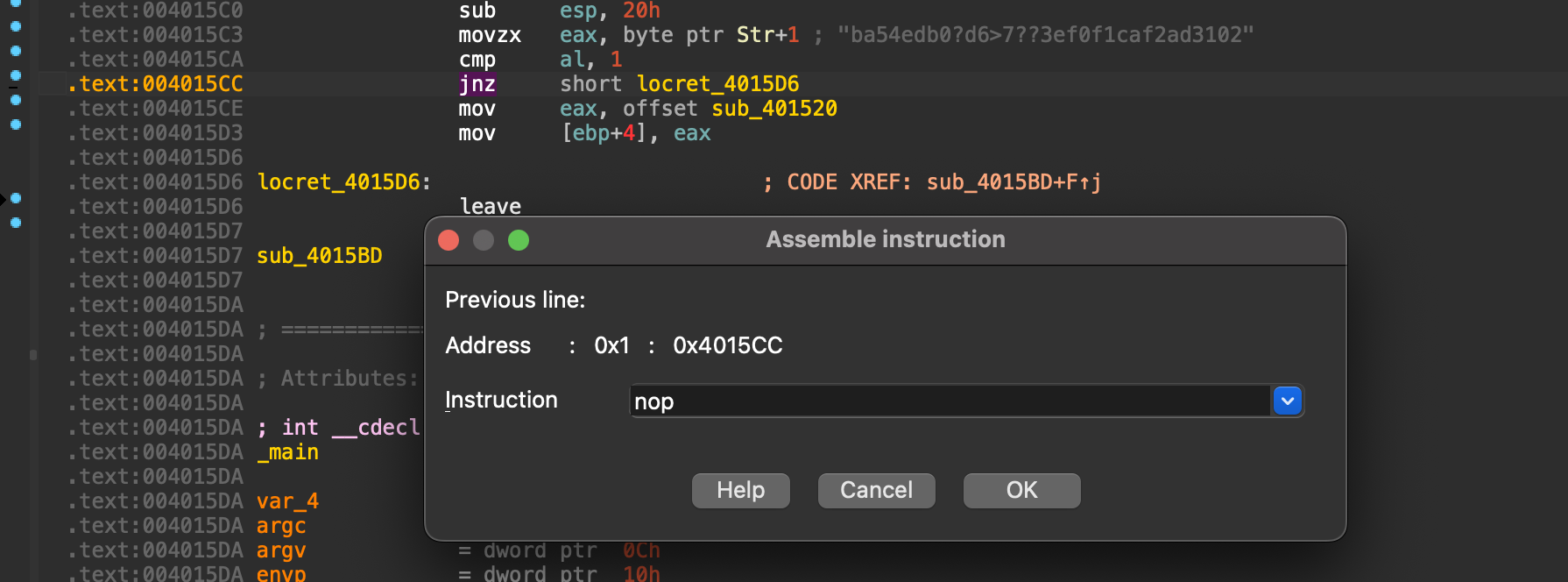
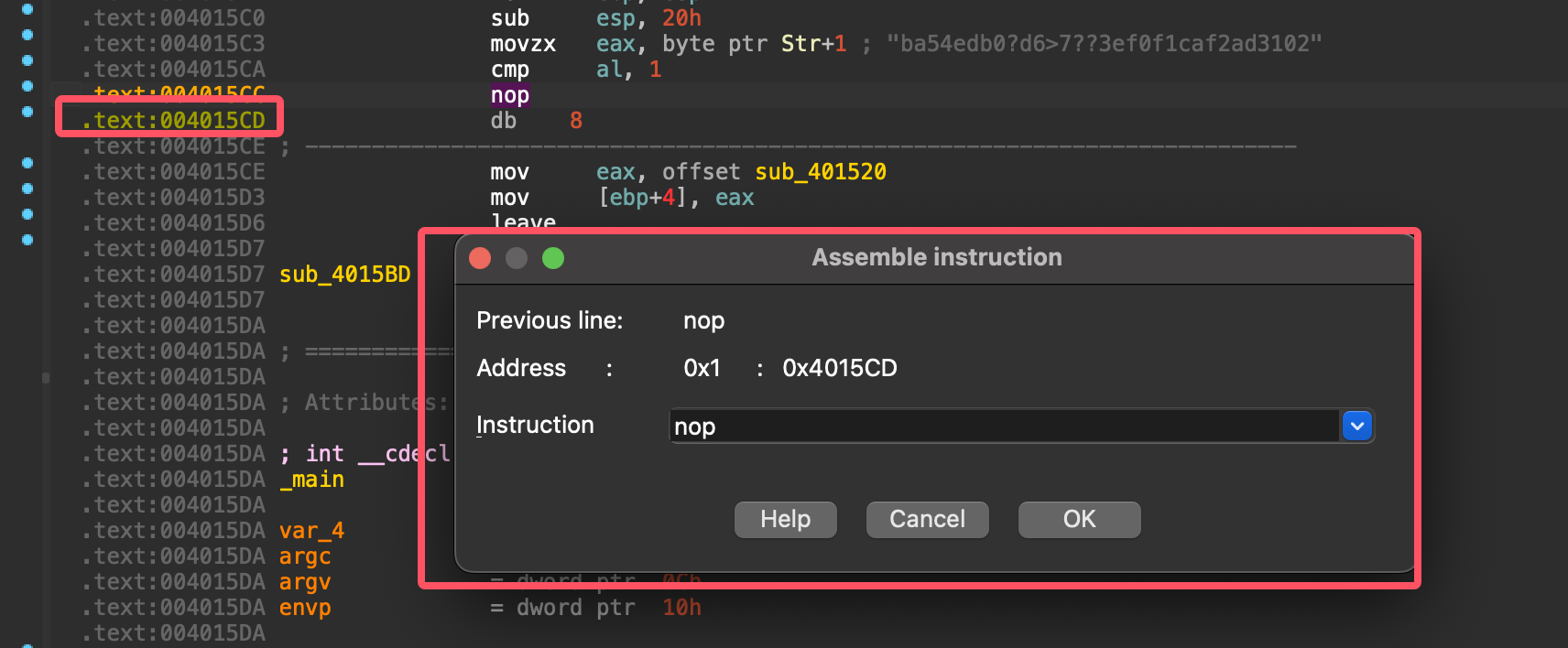
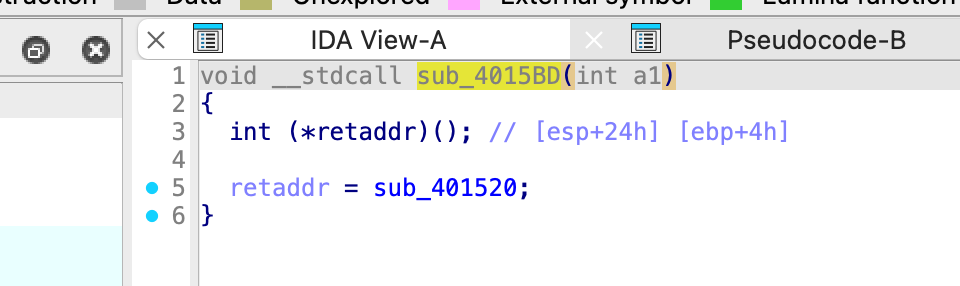
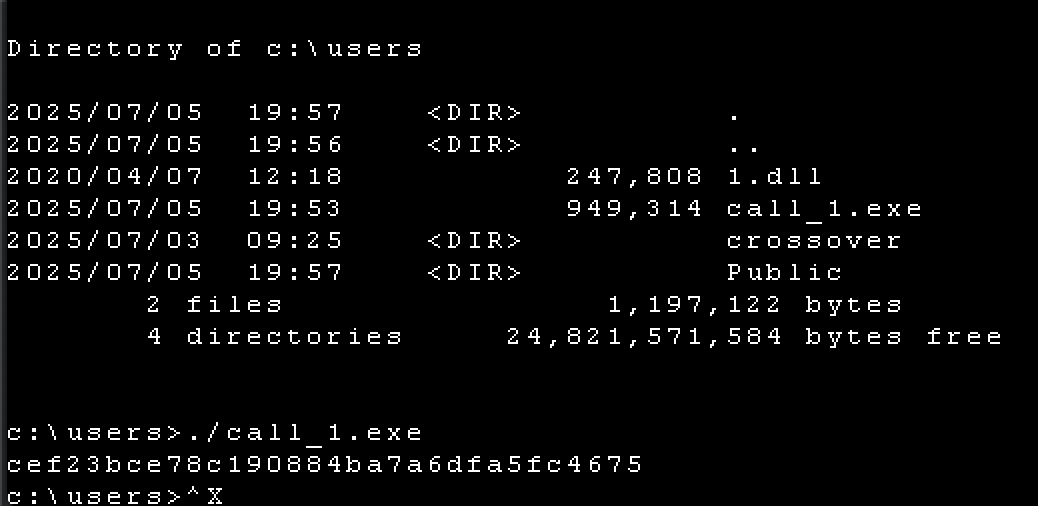
覆盖之后,patch 进文件即可 之后打开终端运行软件命令可以查看到结果
# 武穆遗书
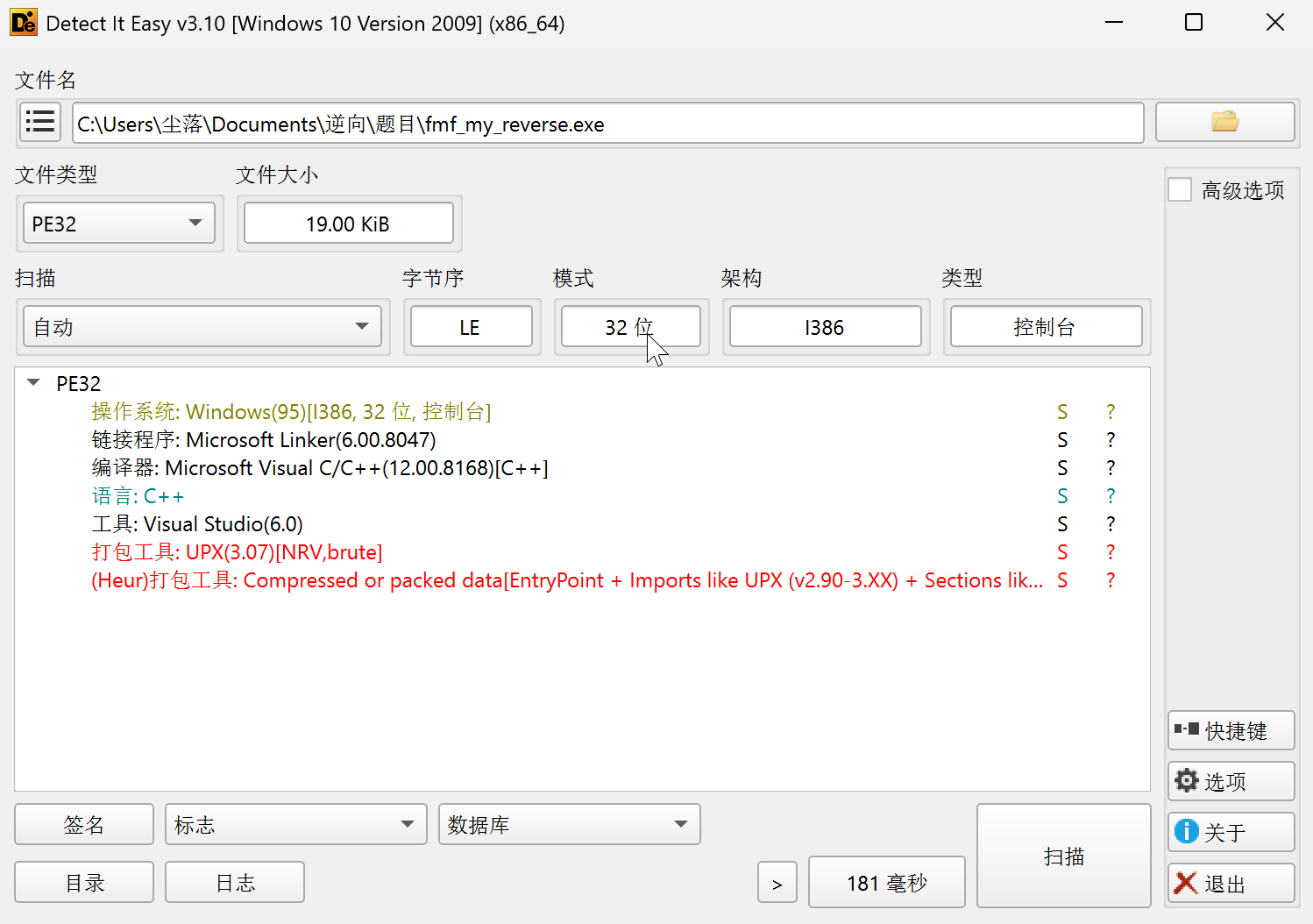
- 使用 die 工具检测软件为 upx 打包方式(加壳),需要去壳
- 使用 x64dbg 打开软件,先执行 F9 进入 ep,但这里只是壳的 ep 我们需要找到 oep;
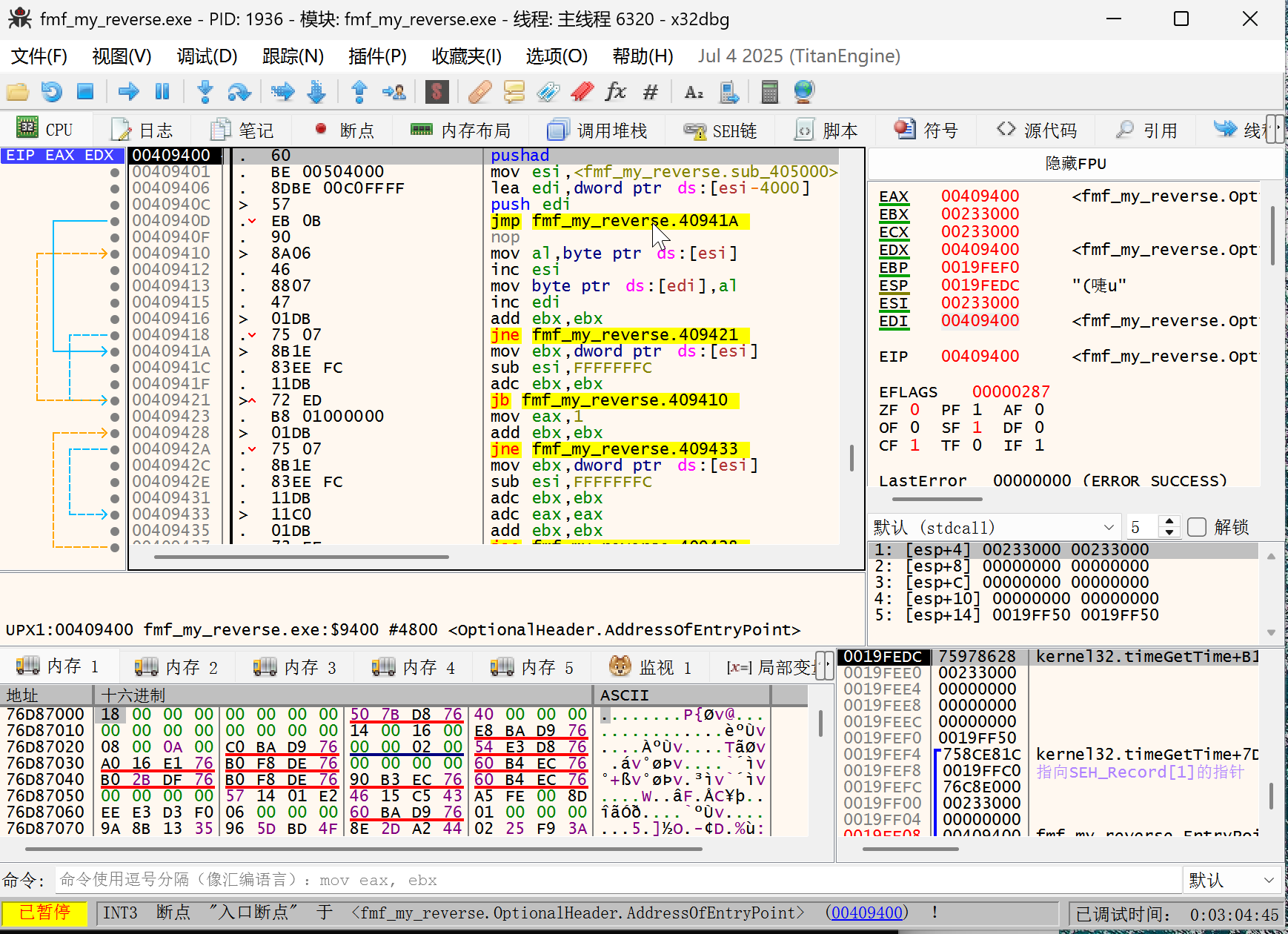
- 由于是 upx 打包,可以看到第一句是 pushad,则找到对应 popad 就能找到源程序的 oep
- Ctrl f 搜索 popad
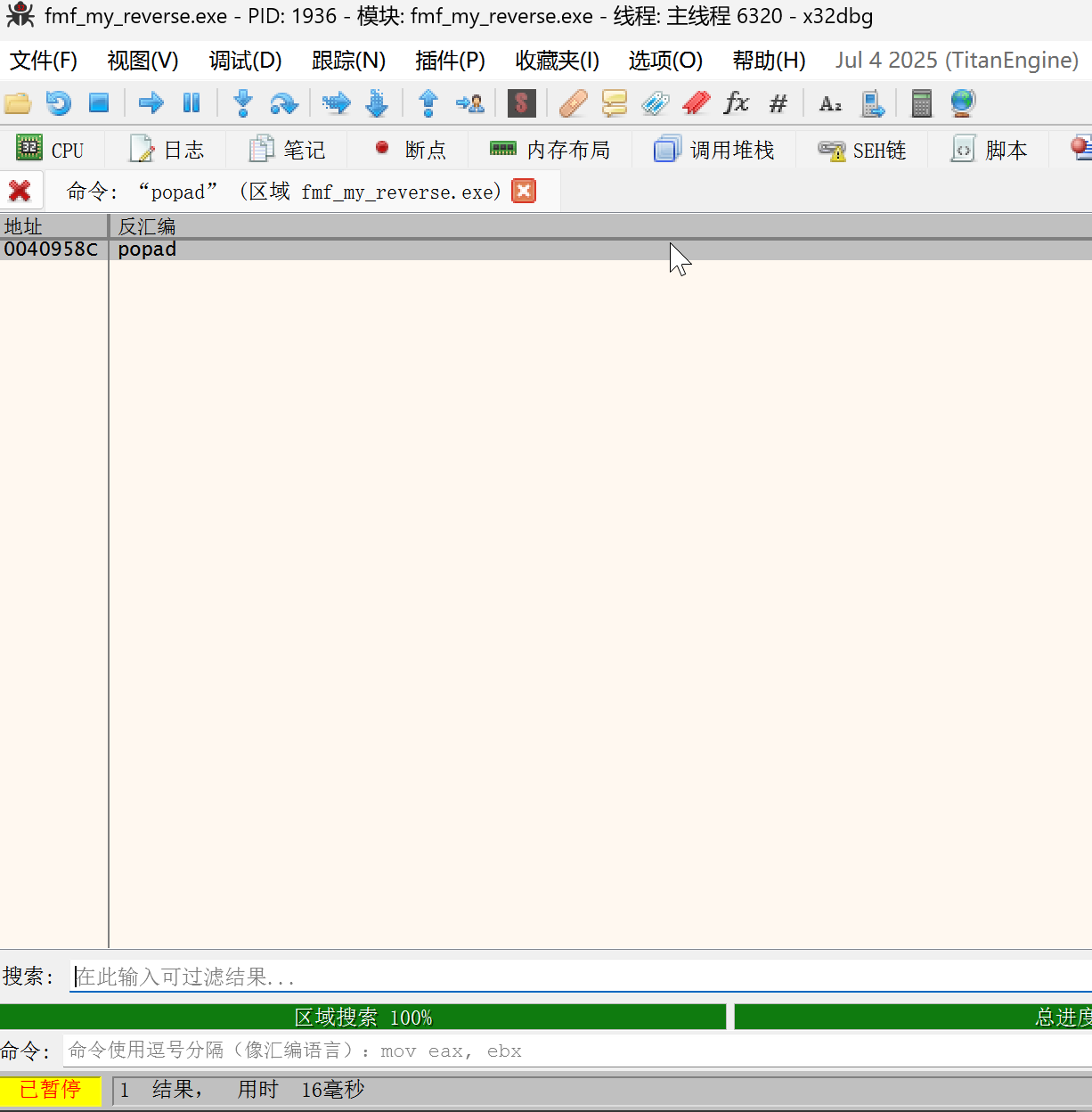
- 找到 popad 之后,早第一个 jmp 语句,即是源程序的 oep,打断点之后执行到 oep
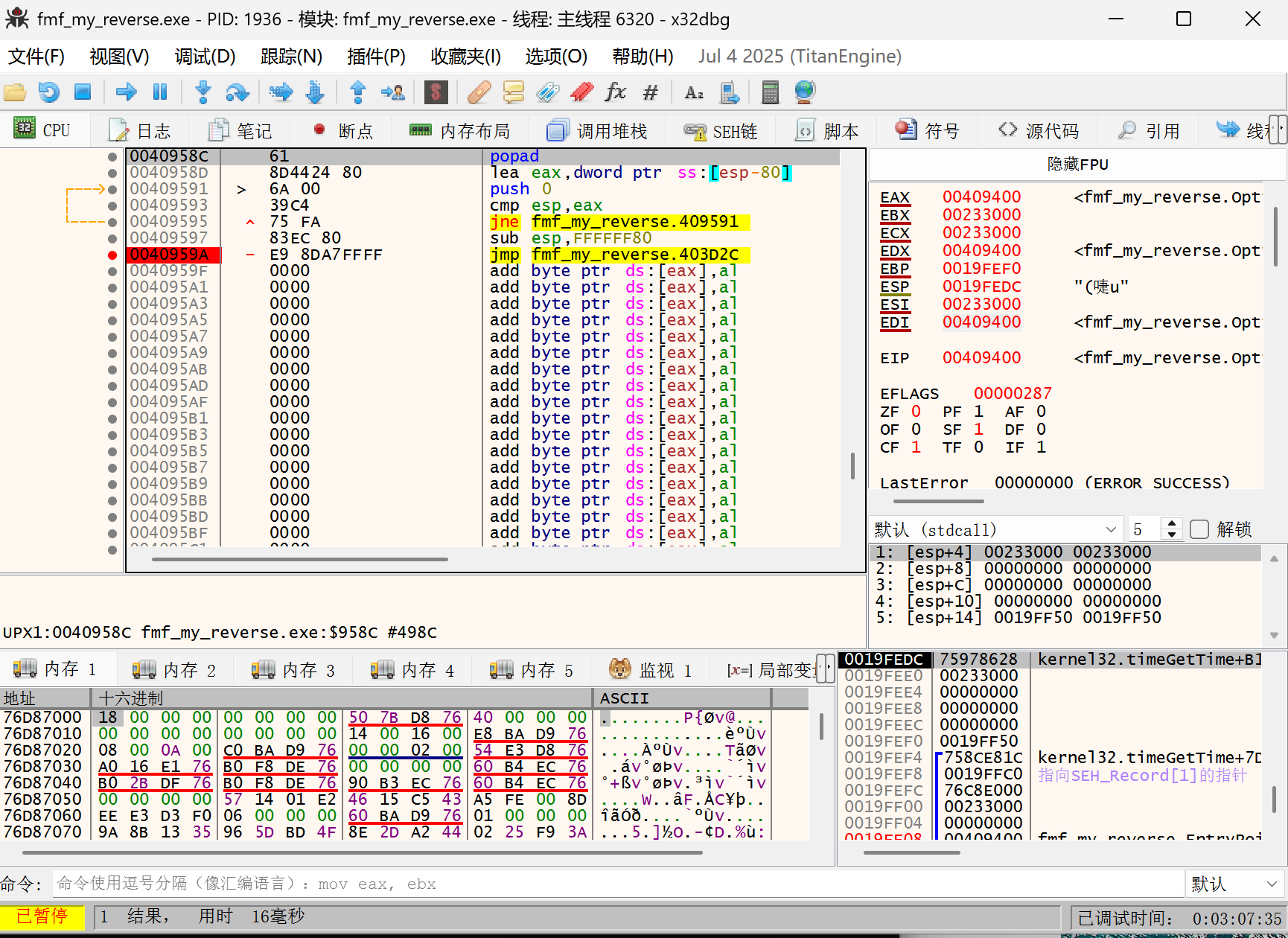
- 进入 403d2c 并选中
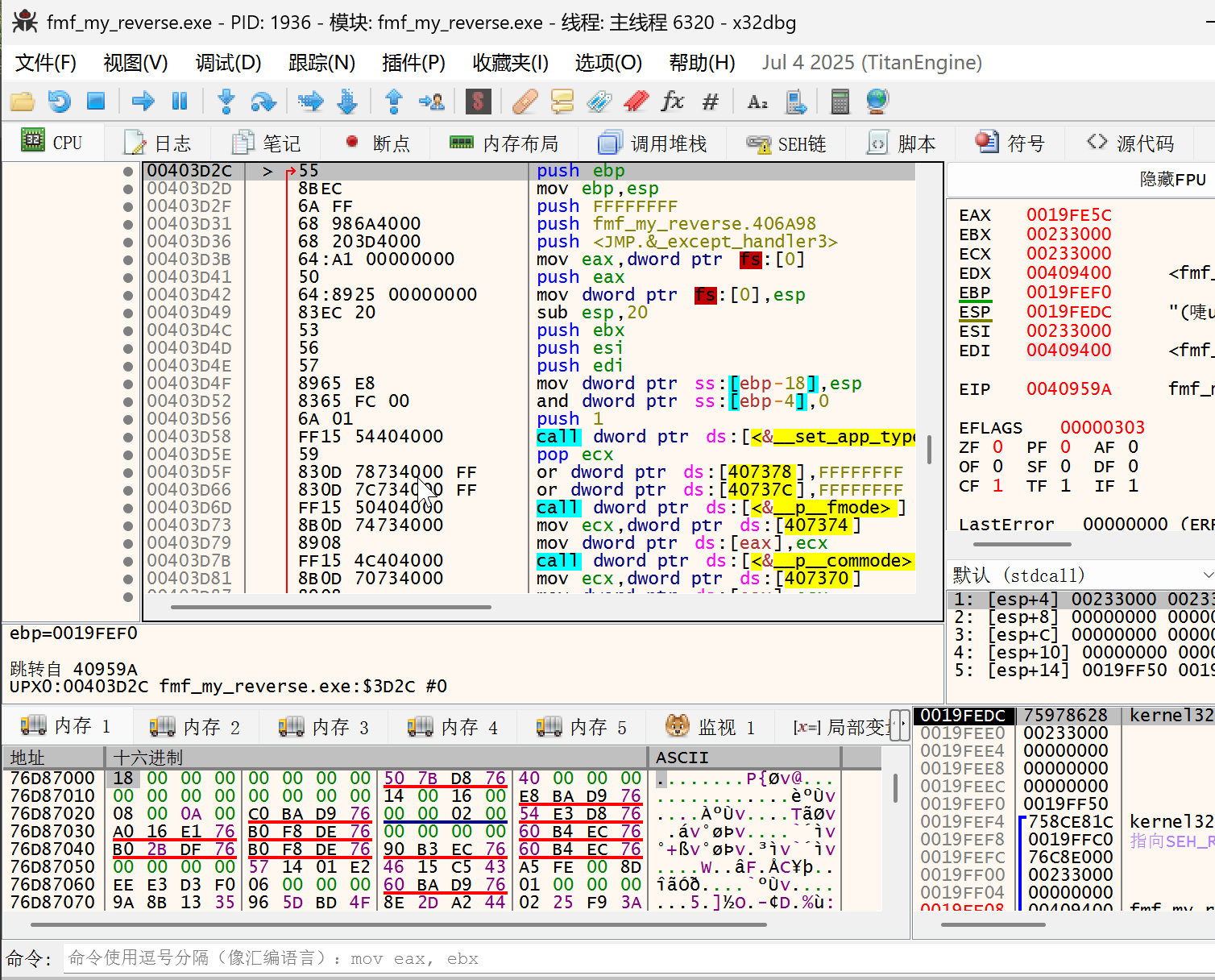
- 使用 scylla 进行脱壳,得到脱壳后的文件
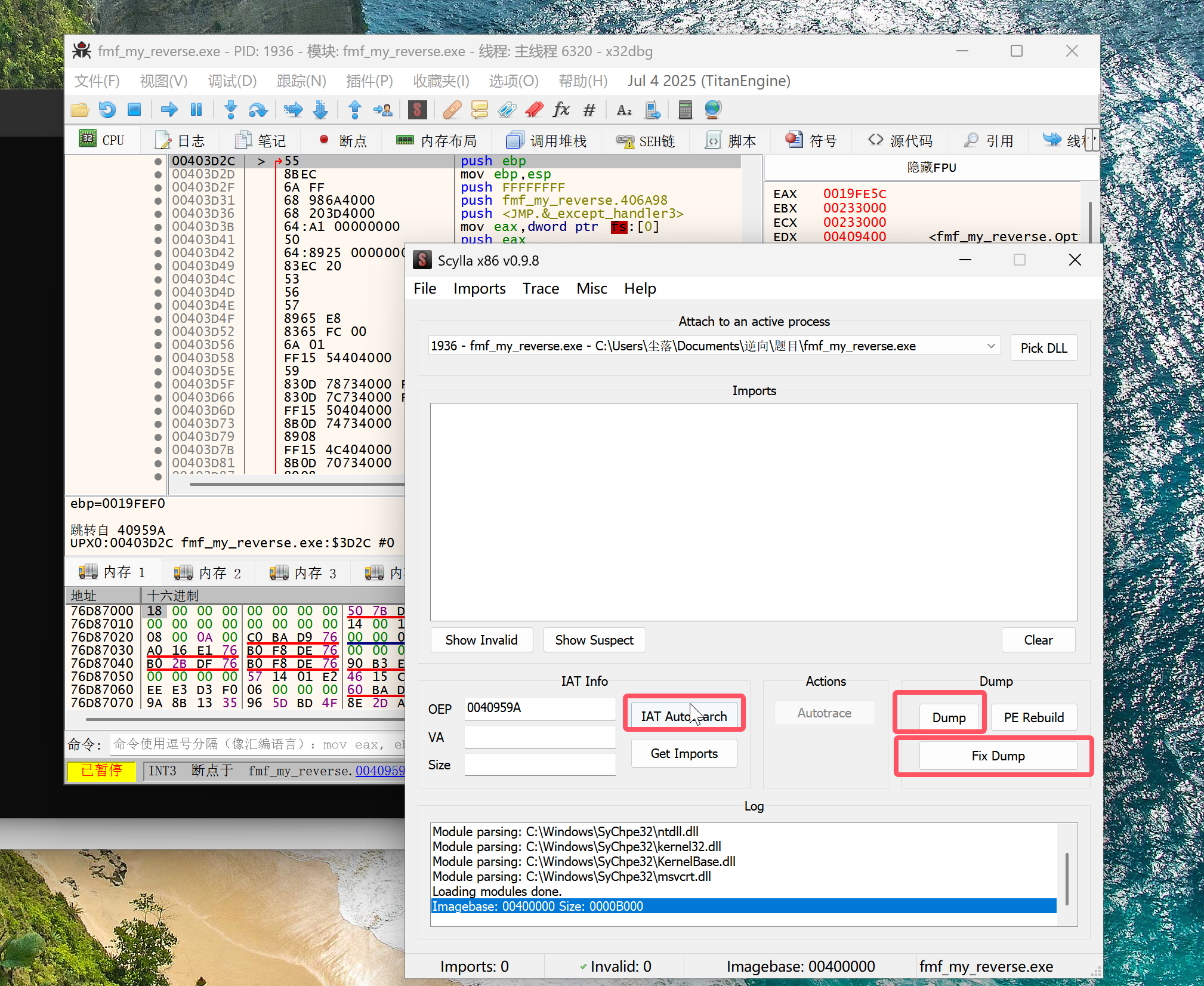
之后使用 IDA 分析脱壳后的文件,前面做了一些反调试和虚拟机检测的操作我们可以直接 nop 掉,使用 x32dbg。
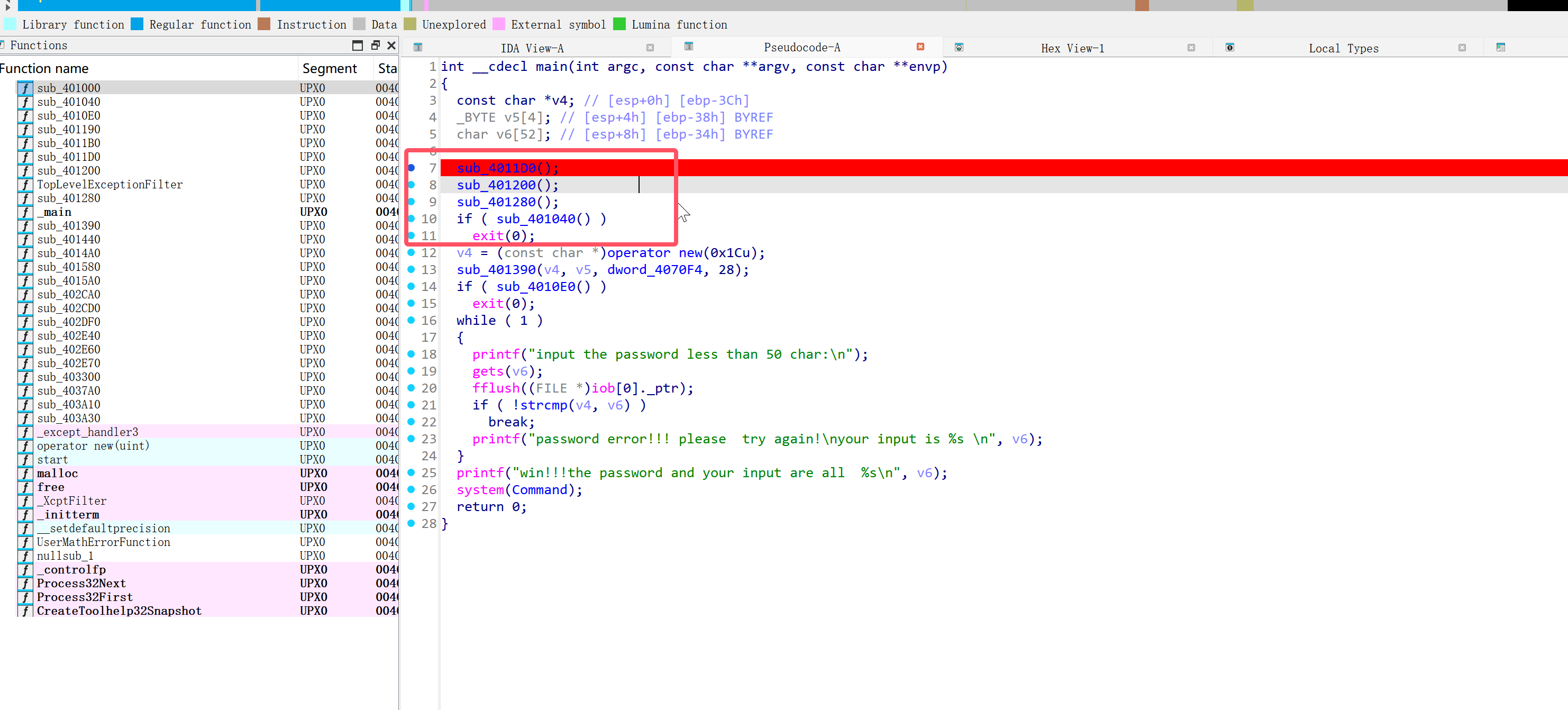
首先通过 IDA 得到这四个初始函数的位置,使用 x32dbg 通过 ctrl g 跳转到这个地址,将这四个函数全部 nop 掉:选中 cll=> 指令点击 Space=> 改成 nop(下面选择剩余字节用 nop 填充)
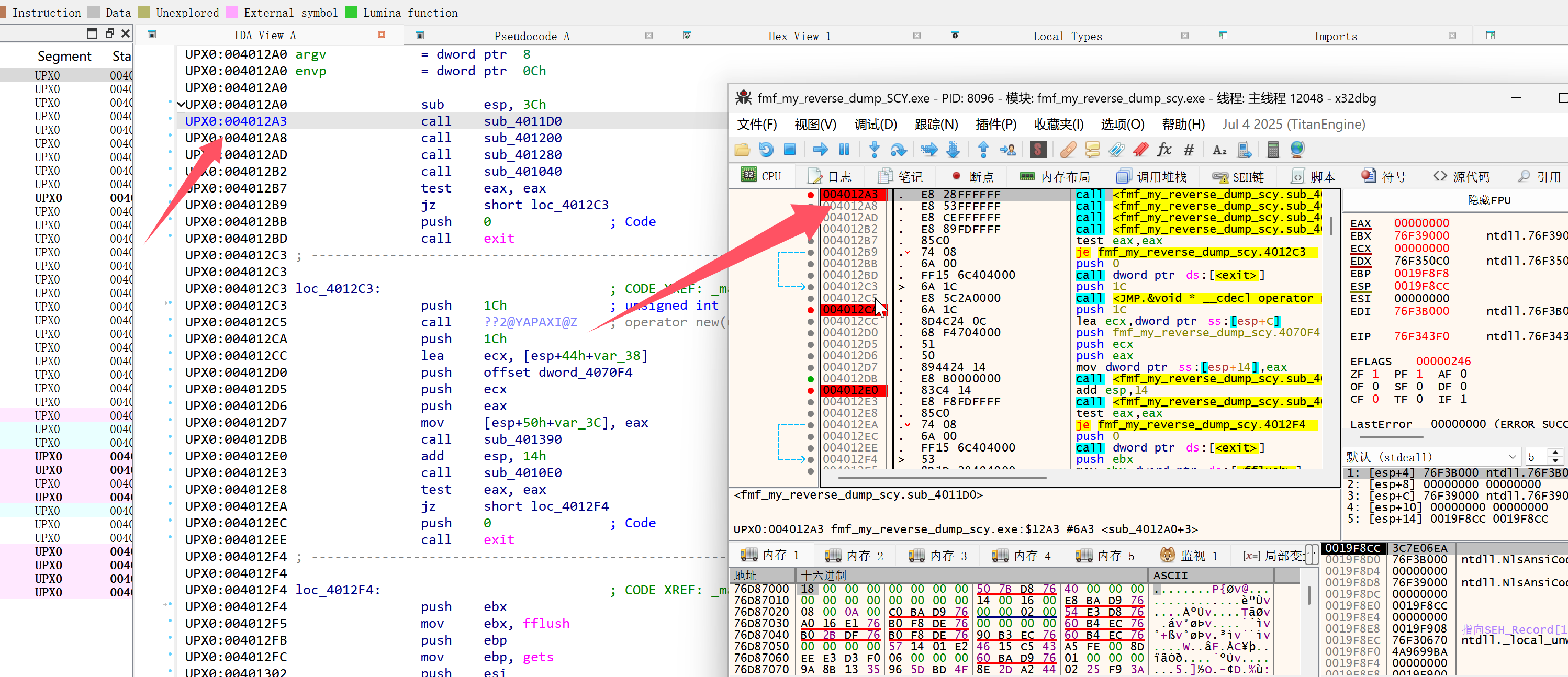
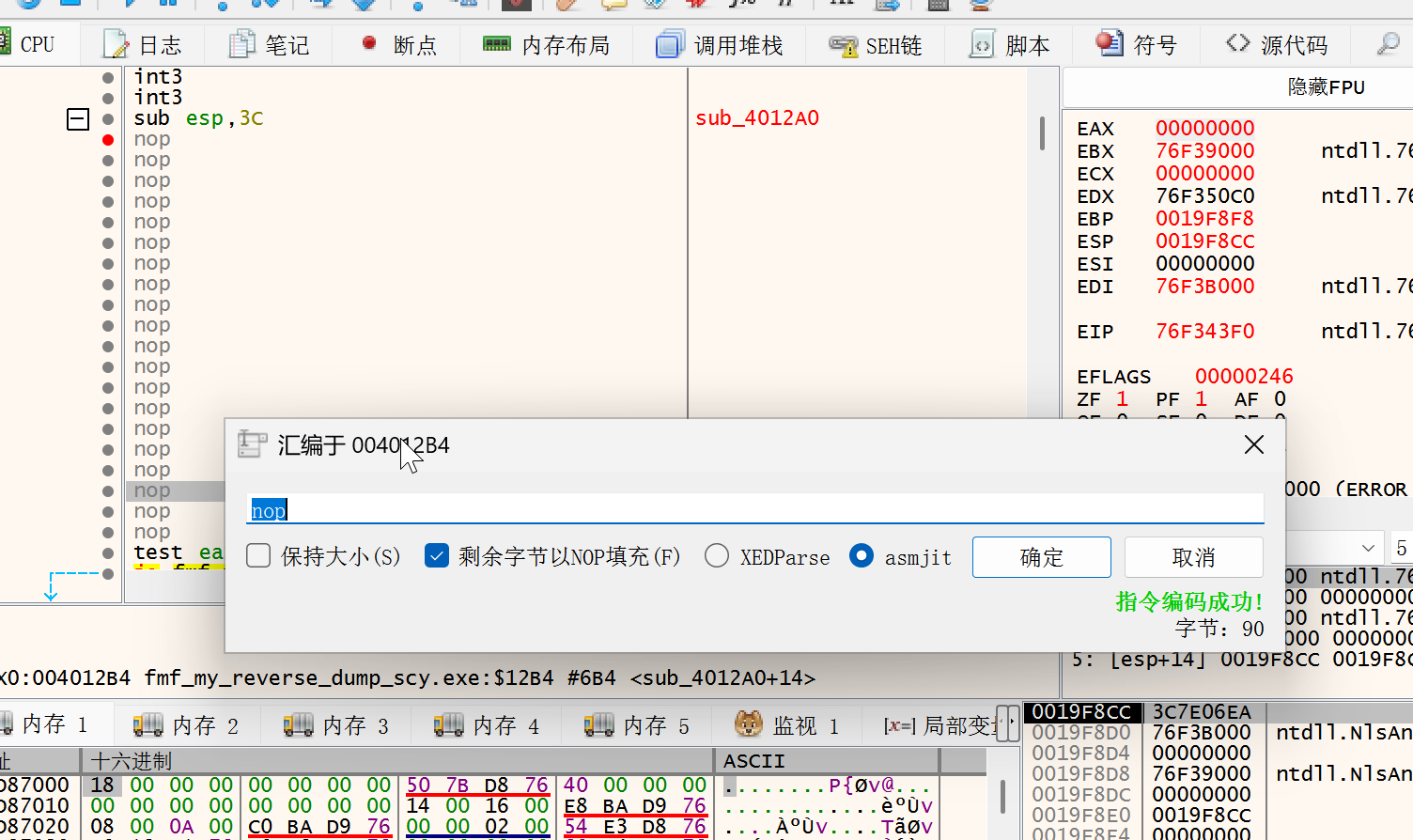
在这些 nop 的地方放置断点,使用 f9 运行到这里后一步一步调试,接下来是 je 指令,默认不会跳转,我们需要修改 zf 标志位改成 1 跳转:
注意:一定是跳转 不能直接把 je 指令 nop 掉除非你把下面的三条指令全部 nop 掉直接执行跳转的位置
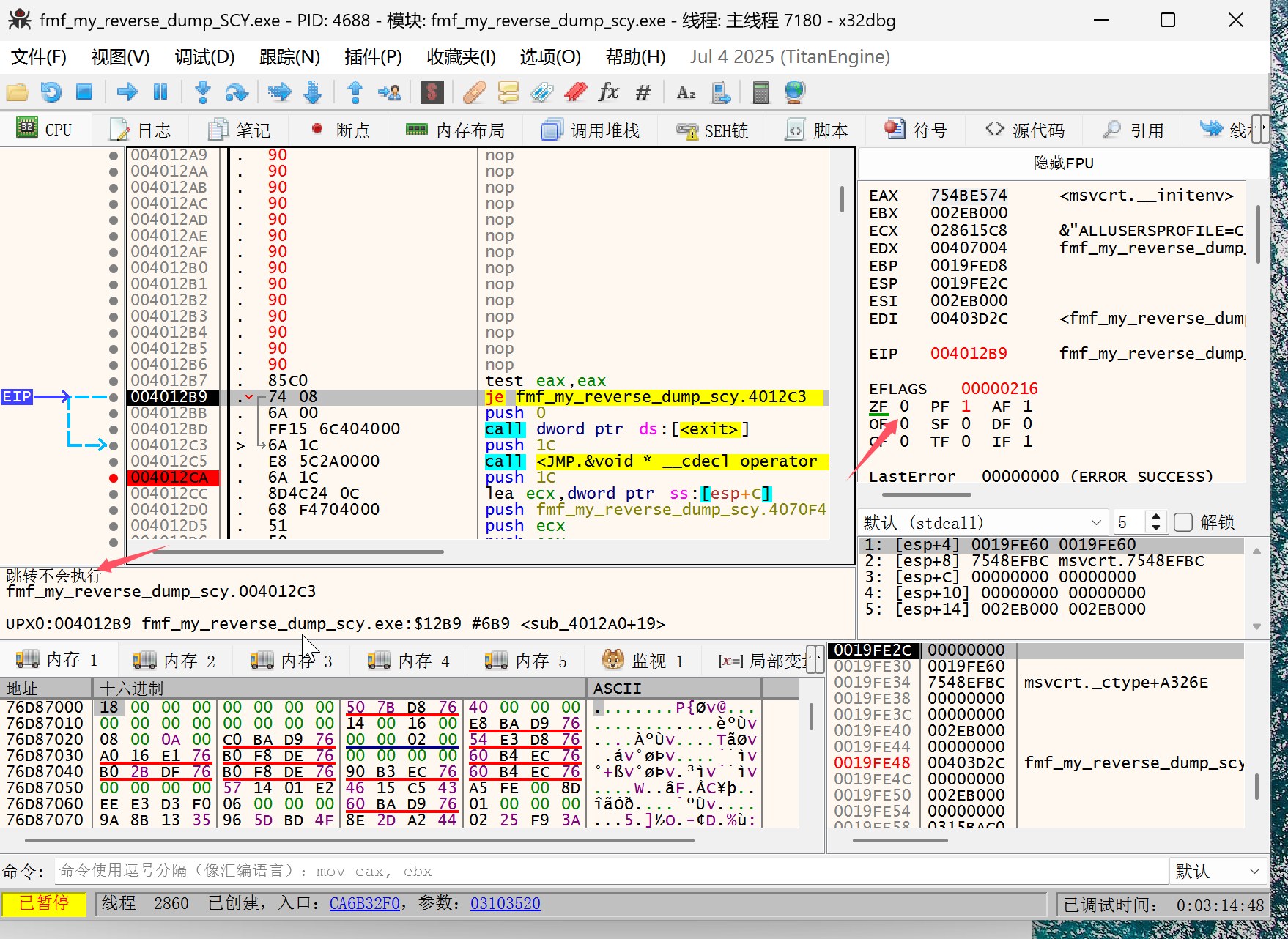
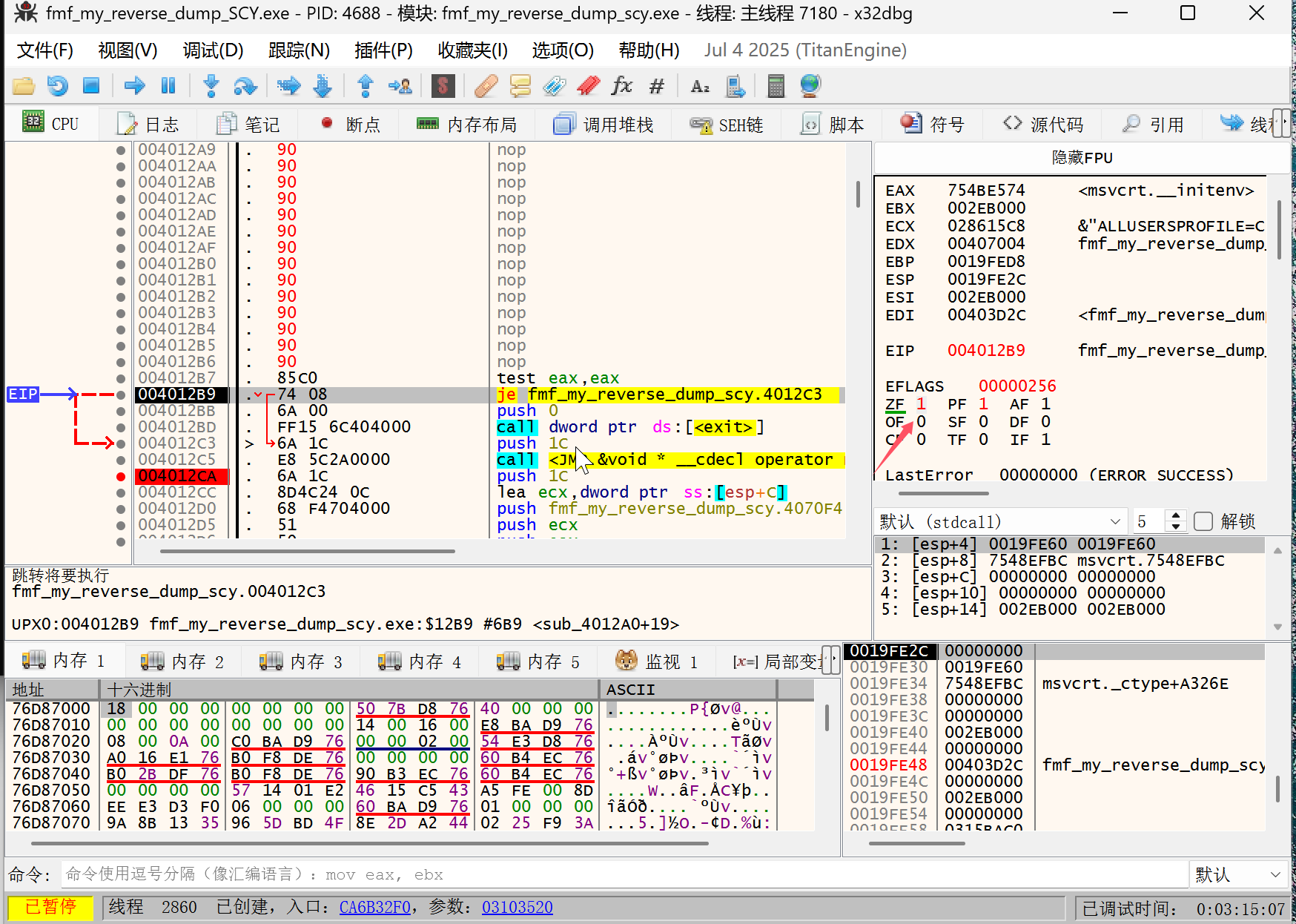
跳转之后,继续执行,直到执行完 401390 函数,就可以直接看到 flag,之后继续执行就是输入和 flag 相同的字符即可。
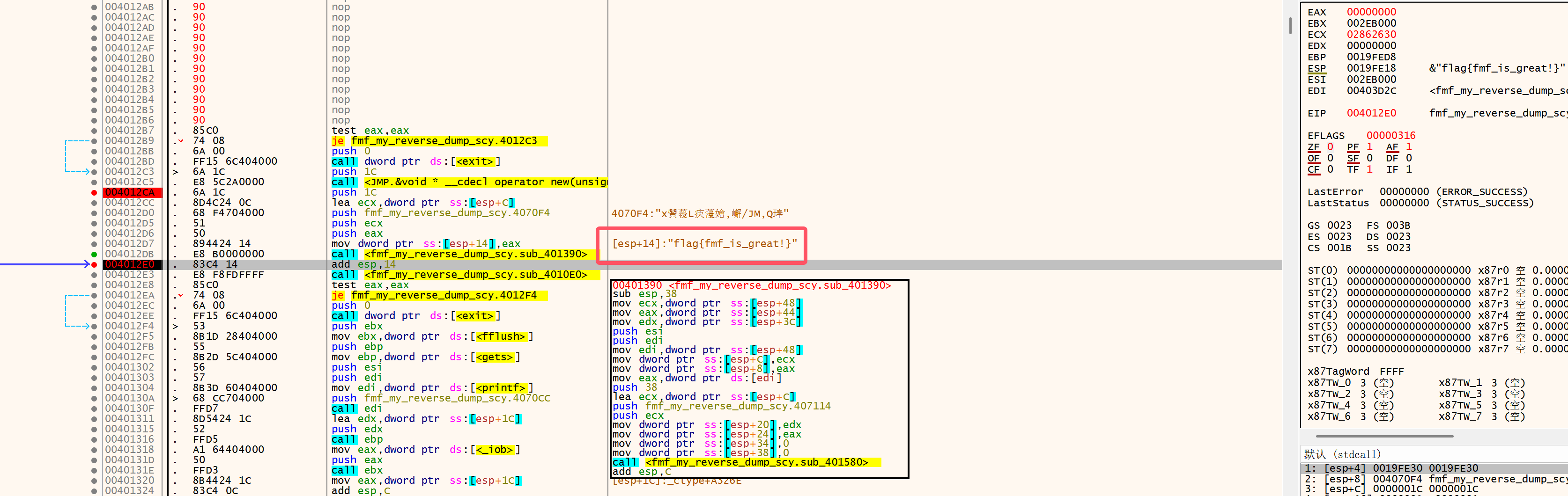
# Re7
下载文件后是个 jar 包,先提取 jar 包中的文件
jar -xf EzJar.jar |
得到两个文件,其中一个 Ez.java
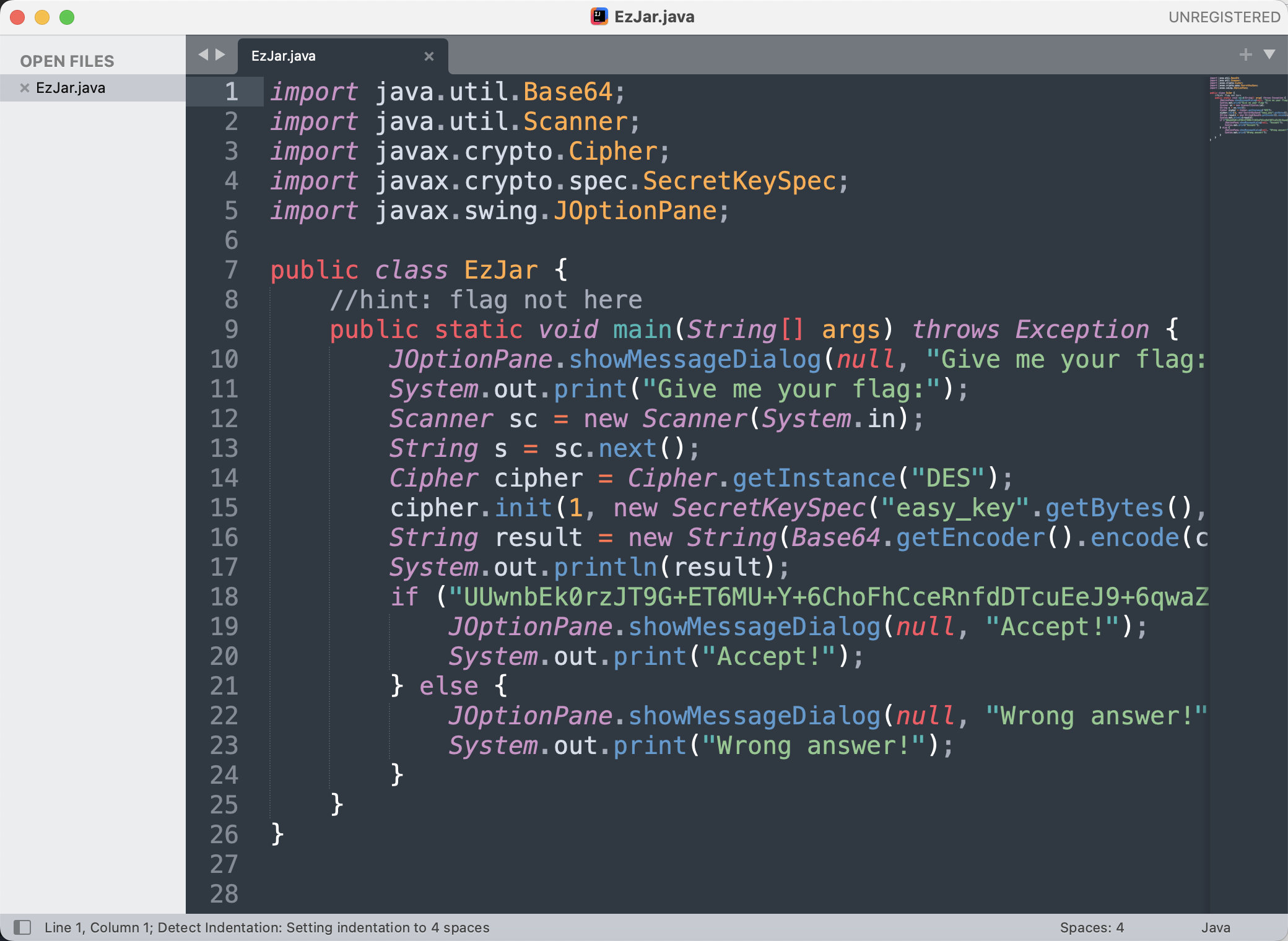
按照上面的思路,发现 flag 不对
之后尝试解析这个下载出来的 jar 包,解析脚本如下:
import zipfile | |
import os | |
import sys | |
import datetime | |
import argparse | |
def analyze_jar(filepath): | |
""" | |
Analyzes the structure of a JAR/ZIP file, showing offsets and appended data. | |
""" | |
if not os.path.exists(filepath): | |
print(f"错误: 文件不存在 '{filepath}'") | |
return | |
print(f"--- 开始分析: {os.path.basename(filepath)} ---") | |
print(f"文件总大小: {os.path.getsize(filepath):,} 字节") | |
print("-" * 40) | |
try: | |
with zipfile.ZipFile(filepath, 'r') as zf: | |
print("[+] 文件列表和内部结构:\n") | |
infolist = zf.infolist() | |
if not infolist: | |
print(" -> 此JAR包为空或无法识别内部文件。") | |
for info in infolist: | |
# ZipInfo 对象包含了丰富的元数据 | |
header_offset = info.header_offset | |
filename = info.filename | |
# 计算压缩数据的真实起始偏移量 | |
# 公式:数据偏移量 = 文件头偏移量 + 30 (固定头大小) + 文件名长度 + 额外字段长度 | |
data_offset = header_offset + 30 + len(filename.encode('utf-8')) + len(info.extra) | |
print(f" 文件名: {filename}") | |
print(f" ├─ 修改时间: {datetime.datetime(*info.date_time)}") | |
print(f" ├─ 文件头偏移量 (Header Offset): {header_offset:<10} (0x{header_offset:08X})") | |
print(f" ├─ 数据偏移量 (Data Offset): {data_offset:<10} (0x{data_offset:08X})") | |
print(f" ├─ 压缩后大小: {info.compress_size:,} 字节") | |
print(f" ├─ 原始大小: {info.file_size:,} 字节") | |
print(f" └─ CRC校验码: 0x{info.CRC:08X}\n") | |
except zipfile.BadZipFile as e: | |
print(f"[!] 严重错误: {e}") | |
print(" -> 文件不是一个有效的JAR/ZIP文件,或者已经严重损坏。") | |
except Exception as e: | |
print(f"[!] 发生未知错误: {e}") | |
# --- 手动检查文件末尾的附加数据 --- | |
print("[+] 附加数据检查:") | |
with open(filepath, 'rb') as f: | |
# ZIP 文件的结尾记录(EOCD)标志是 PK\x05\x06 | |
eocd_signature = b'\x50\x4B\x05\x06' | |
# 从文件末尾开始搜索,效率更高 | |
f.seek(0, os.SEEK_END) | |
filesize = f.tell() | |
# 我们只在文件末尾一小块区域内搜索,以防万一 | |
read_buffer = max(0, filesize - 65536) | |
f.seek(read_buffer) | |
data = f.read() | |
eocd_pos_in_data = data.rfind(eocd_signature) | |
if eocd_pos_in_data == -1: | |
print(" -> 未找到标准的ZIP文件结尾记录 (EOCD)。") | |
print(" 这证实了 'zip END header not found' 错误。文件可能不完整。") | |
else: | |
eocd_abs_pos = read_buffer + eocd_pos_in_data | |
# EOCD 记录中,注释长度字段在偏移量 20 处,占 2 字节 | |
comment_len_bytes = data[eocd_pos_in_data + 20: eocd_pos_in_data + 22] | |
comment_len = int.from_bytes(comment_len_bytes, 'little') | |
# ZIP 文件的理论结束位置 | |
expected_end = eocd_abs_pos + 22 + comment_len | |
print(f" -> 找到文件结尾记录 (EOCD) 在偏移量: {eocd_abs_pos}") | |
print(f" -> ZIP结构理论结束位置: {expected_end}") | |
if filesize > expected_end: | |
appended_size = filesize - expected_end | |
print(f" -> [!] 警告: 文件末尾发现 {appended_size:,} 字节的附加数据!") | |
else: | |
print(" -> 正常: 未发现附加数据。") | |
print("-" * 40) | |
print("--- 分析结束 ---") | |
if __name__ == '__main__': | |
parser = argparse.ArgumentParser(description="分析一个JAR/ZIP文件的内部结构、偏移量和附加数据。") | |
parser.add_argument("jarfile", help="需要分析的JAR文件路径") | |
args = parser.parse_args() | |
analyze_jar(args.jarfile) |
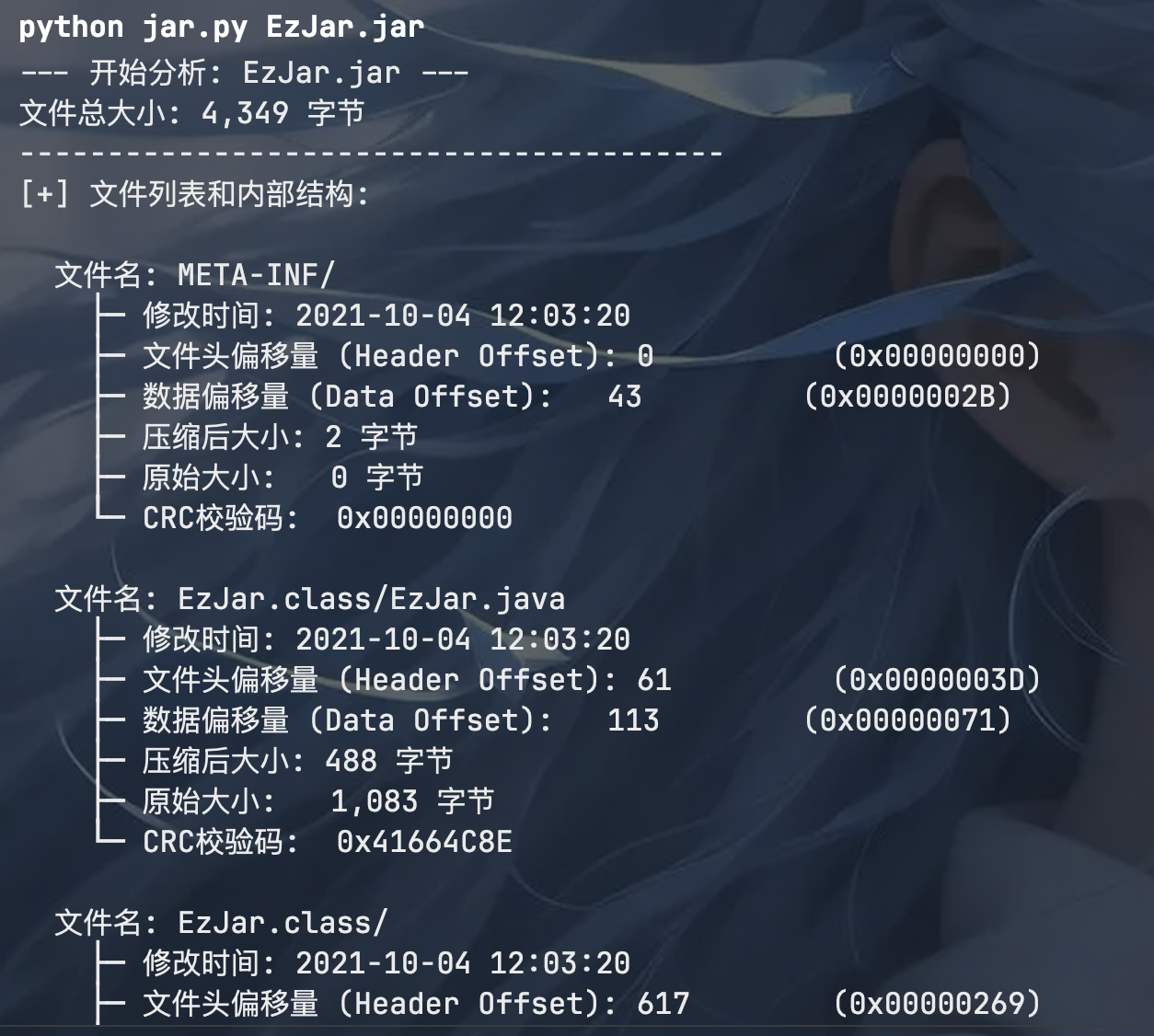
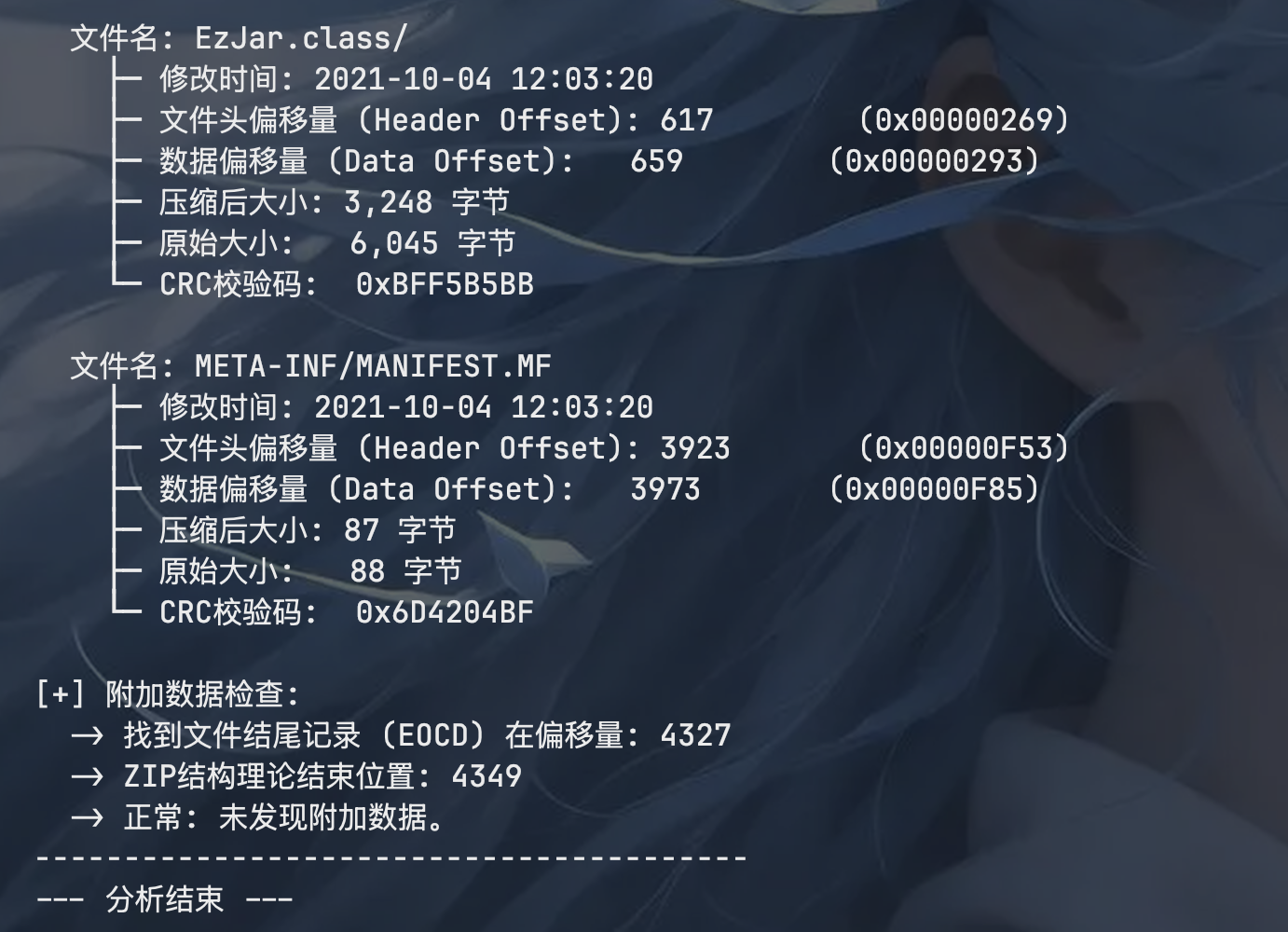
可以看到一个异常 EzJar.class/ 这个文件没被解压出来而且大小是 6000 字节,很显然有问题,可尝试分离 jar 包:
import zipfile | |
import argparse | |
import os | |
def separate_jar_components_v2(source_jar_path): | |
OBFUSCATED_SOURCE_NAME = 'EzJar.class/EzJar.java' | |
OBFUSCATED_BYTECODE_NAME = 'EzJar.class/' | |
OUTPUT_SOURCE_JAR = 'source_code.jar' | |
OUTPUT_BYTECODE_JAR = 'compiled_bytecode.jar' | |
CLEAN_SOURCE_NAME = 'EzJar.java' | |
CLEAN_BYTECODE_NAME = 'EzJar.class' | |
# 标准清单文件的内容 | |
# MANIFEST_CONTENT = "Manifest-Version: 1.0\n\n" | |
MANIFEST_CONTENT = "Manifest-Version: 1.0\nMain-Class: EzJar\n\n" | |
MANIFEST_PATH = "META-INF/MANIFEST.MF" | |
if not os.path.exists(source_jar_path): | |
print(f"错误: 源文件不存在 '{source_jar_path}'") | |
return | |
source_data = None | |
bytecode_data = None | |
print(f"--- 正在分析 '{source_jar_path}' ---") | |
try: | |
with zipfile.ZipFile(source_jar_path, 'r') as zf: | |
for info in zf.infolist(): | |
if info.filename == OBFUSCATED_SOURCE_NAME: | |
source_data = zf.read(info) | |
elif info.filename == OBFUSCATED_BYTECODE_NAME: | |
bytecode_data = zf.read(info) | |
# 创建源代码 JAR | |
if source_data: | |
print(f"正在创建标准源代码包 -> '{OUTPUT_SOURCE_JAR}'...") | |
with zipfile.ZipFile(OUTPUT_SOURCE_JAR, 'w', compression=zipfile.ZIP_DEFLATED) as zf_source: | |
# 添加清单文件 | |
zf_source.writestr(MANIFEST_PATH, MANIFEST_CONTENT) | |
# 添加源代码文件 | |
zf_source.writestr(CLEAN_SOURCE_NAME, source_data) | |
print(f" -> 成功创建 '{OUTPUT_SOURCE_JAR}'") | |
# 创建字节码 JAR | |
if bytecode_data: | |
print(f"正在创建标准字节码包 -> '{OUTPUT_BYTECODE_JAR}'...") | |
with zipfile.ZipFile(OUTPUT_BYTECODE_JAR, 'w', compression=zipfile.ZIP_DEFLATED) as zf_bytecode: | |
# 添加清单文件 | |
zf_bytecode.writestr(MANIFEST_PATH, MANIFEST_CONTENT) | |
# 添加字节码文件 | |
zf_bytecode.writestr(CLEAN_BYTECODE_NAME, bytecode_data) | |
print(f" -> 成功创建 '{OUTPUT_BYTECODE_JAR}'") | |
print("\n--- 分离完成 ---") | |
except Exception as e: | |
print(f"[!] 处理过程中发生错误: {e}") | |
if __name__ == '__main__': | |
parser = argparse.ArgumentParser(description="将一个混淆的JAR文件分离成两个包含标准清单的、干净的JAR文件。") | |
parser.add_argument("source_jar", help="原始的、被混淆的JAR文件路径。") | |
args = parser.parse_args() | |
separate_jar_components_v2(args.source_jar) |
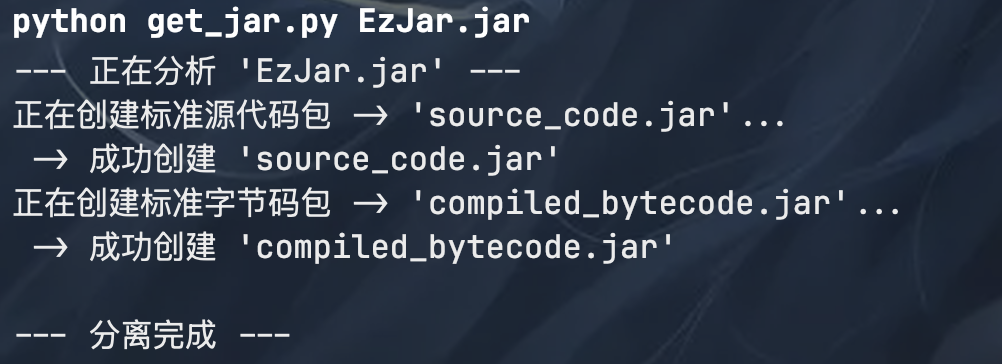
compiled_bytecode.jar 是我们分离的 jar 包,接下来使用 jd 或者直接在 idea 反编译这个 jar 包,可以直接读到伪代码
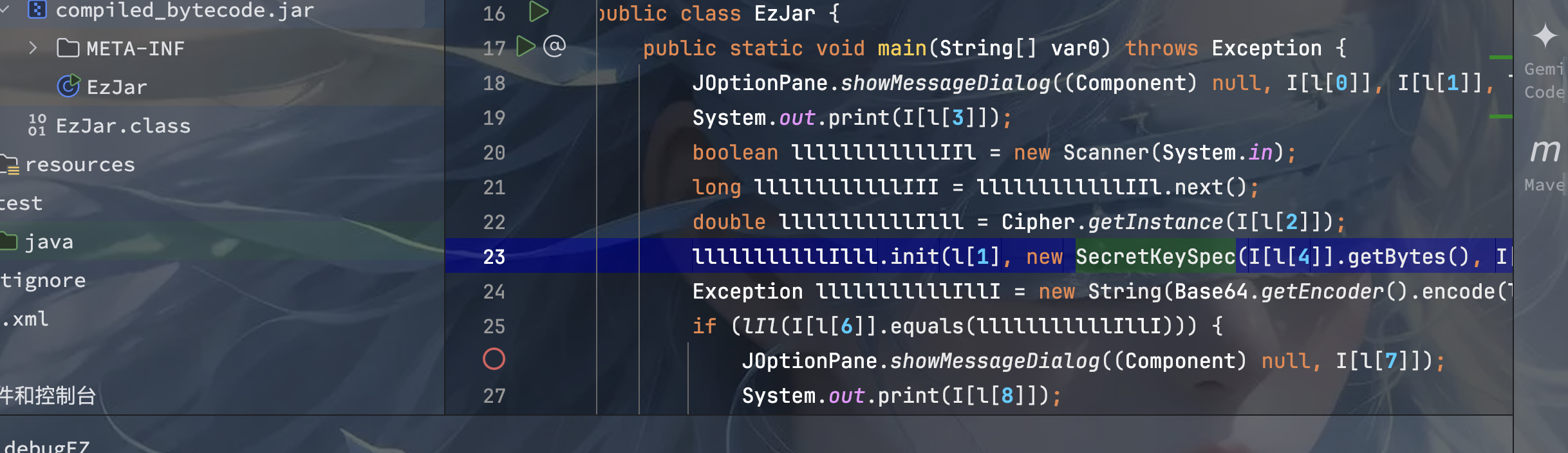
根据代码逻辑写一个复现脚本,找到密文,密钥之后解密:
import base64 | |
import hashlib | |
from Crypto.Cipher import DES, Blowfish | |
from Crypto.Util.Padding import unpad | |
# 全局变量,用于存储 Java 代码中的 l 和 I 数组 | |
l = [0] * 18 | |
I = [""] * 17 | |
def lII(): | |
"""复刻Java的lII()方法,计算出l[]数组的值""" | |
global l | |
l[0] = (156 ^ 136) & ~(127 ^ 107) | |
l[1] = 1 | |
l[2] = 3 | |
l[3] = 2 | |
l[4] = 185 ^ 197 ^ 32 ^ 88 | |
l[5] = 1 ^ 28 ^ 24 | |
l[6] = 16 ^ 22 | |
l[7] = 69 ^ 77 ^ 70 ^ 73 | |
l[8] = (106 + 107 - 66 + 32) ^ (33 + 90 - 98 + 162) | |
l[9] = (154 + 21 - 48 + 38) ^ (78 + 146 - 163 + 111) | |
l[10] = 29 ^ 23 | |
l[11] = 64 ^ 75 | |
l[12] = 105 ^ 101 | |
l[13] = 2 ^ 106 ^ 101 | |
l[14] = 72 ^ 70 | |
l[15] = 144 ^ 159 | |
l[16] = 160 ^ 176 | |
l[17] = 177 ^ 160 | |
def decrypt_l(b64_str, key_str): | |
"""复刻Java的l()方法 (XOR解密)""" | |
decoded_bytes = base64.b64decode(b64_str) | |
key_bytes = key_str.encode('utf-8') | |
result = bytearray() | |
for i in range(len(decoded_bytes)): | |
result.append(decoded_bytes[i] ^ key_bytes[i % len(key_bytes)]) | |
return result.decode('utf-8') | |
def decrypt_lI(b64_str, key_str): | |
"""复刻Java的lI()方法 (Blowfish解密)""" | |
key = hashlib.md5(key_str.encode('utf-8')).digest() | |
cipher = Blowfish.new(key, Blowfish.MODE_ECB) | |
decoded_bytes = base64.b64decode(b64_str) | |
return unpad(cipher.decrypt(decoded_bytes), Blowfish.block_size).decode('utf-8') | |
def decrypt_I(b64_str, key_str): | |
"""复刻Java的I()方法 (DES解密)""" | |
# Java 的 Arrays.copyOf (..., 8) 相当于取前 8 个字节 | |
key = hashlib.md5(key_str.encode('utf-8')).digest()[:8] | |
cipher = DES.new(key, DES.MODE_ECB) | |
decoded_bytes = base64.b64decode(b64_str) | |
return unpad(cipher.decrypt(decoded_bytes), DES.block_size).decode('utf-8') | |
def ll(): | |
"""复刻Java的ll()方法,解密并填充I[]数组""" | |
global I, l | |
I[l[0]] = decrypt_I("AQiA0bYffm9HvMlm7RnEMX/tEQAUj4Xb", "FrlAZ") | |
I[l[1]] = decrypt_I("hXzZyx8IUHw=", "Esxsh") | |
I[l[3]] = decrypt_l("ID8PFlEKM1kKHhIkWRUdBjFD", "gVysq") | |
I[l[2]] = decrypt_I("50fO6ARqllg=", "VZbFF") | |
I[l[4]] = decrypt_lI("mvXqH+/XIESPZaSG3ZbZlA==", "TuZSw") | |
I[l[5]] = decrypt_l("JQ0R", "aHBFu") | |
I[l[6]] = decrypt_I( | |
"dMKiRQ19iTevvzL7NtVg5+ye5BywL2QaxtVANFLuC5B2/KuC+/5L6BwtCB7zpWK1XBTQr0VWC3Vt/uYEl2xmjskE0dDrCk2C", "dPxYA") | |
I[l[7]] = decrypt_lI("B/MVYKSzgq8=", "phiUP") | |
I[l[8]] = decrypt_I("ZtBOhuHeK3Y=", "MfnkQ") | |
I[l[9]] = decrypt_lI("aPhz+GjGynRlU3Alo00QeQ==", "wWtUj") | |
I[l[10]] = decrypt_l("BRQFNiRyBwQrNDcUSw==", "RfjXC") | |
I[l[11]] = decrypt_I("pT10j0lChvyrNwYRFdqBzxqFp1ruTgo9", "hGcuT") | |
I[l[12]] = decrypt_lI( | |
"UhBbCDk5yqaWl1uHJyS/OGmtcfVyvOOsk78/1f0MU8U3UfAf1Xf0FWNbpcKes/0HRz9SU/icRJHswW2xWjHrcFzhpsvwzqUl", "eeMoV") | |
I[l[13]] = decrypt_I("s11BihYBzRBpcX9EF43utw==", "RjiXK") | |
I[l[14]] = decrypt_I("wk5jH1cyKoA=", "frsxP") | |
I[l[15]] = decrypt_I("Nfa0rxB8IRArMq2F4iLlLg==", "ulQWJ") | |
I[l[16]] = decrypt_lI("wLcWNd0Xsbw=", "JgPGn") | |
def final_crack(): | |
"""执行最终的核心破解逻辑""" | |
print("[+] 正在复刻Java内部的解密过程...") | |
# 步骤一:初始化常量数组 l 和 I | |
lII() | |
ll() | |
print("[+] 已成功解密并重建所有隐藏字符串。") | |
# 步骤二:从重建的数组中获取关键信息 | |
# main 方法中的密钥是 I [l [4]],l [4] 的值是 4 | |
main_logic_key_str = I[l[4]] | |
# main 方法中的目标密文是 I [l [6]],l [6] 的值是 6 | |
main_logic_ciphertext_b64 = I[l[6]] | |
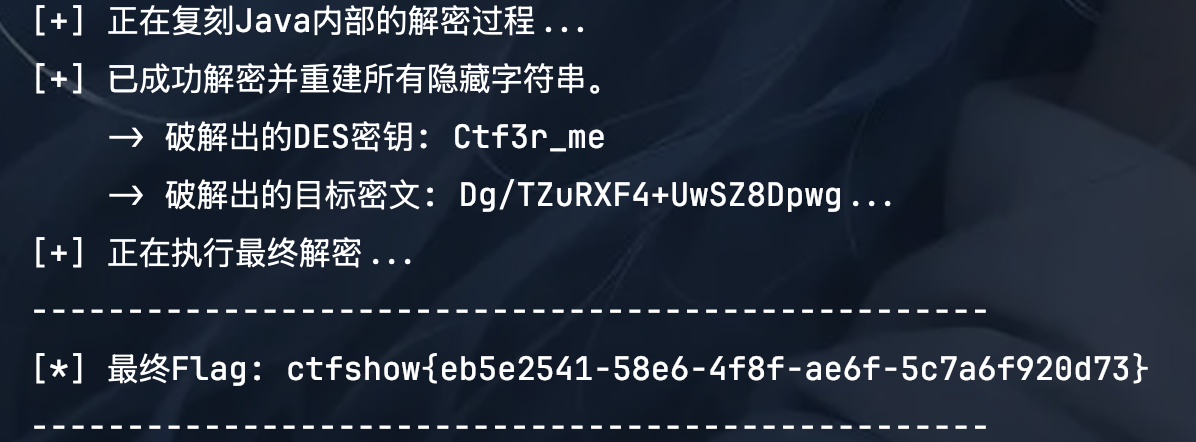
print(f" -> 破解出的DES密钥: {main_logic_key_str}") | |
print(f" -> 破解出的目标密文: {main_logic_ciphertext_b64[:20]}...") | |
# 步骤三:执行最终的 DES 解密 | |
print("[+] 正在执行最终解密...") | |
key_bytes = main_logic_key_str.encode('utf-8') | |
ciphertext_bytes = base64.b64decode(main_logic_ciphertext_b64) | |
cipher = DES.new(key_bytes, DES.MODE_ECB) | |
decrypted_padded_bytes = cipher.decrypt(ciphertext_bytes) | |
# 移除填充 | |
flag = unpad(decrypted_padded_bytes, DES.block_size).decode('utf-8') | |
print("-" * 50) | |
print(f"[*] 最终Flag: {flag}") | |
print("-" * 50) | |
if __name__ == '__main__': | |
final_crack() |